AWS Big Data Blog
Query your Amazon MSK topics interactively using Amazon Managed Service for Apache Flink Studio
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more.
Amazon Managed Service for Apache Flink Studio makes it easy to analyze streaming data in real time and build stream processing applications powered by Apache Flink using standard SQL, Python, and Scala. With a few clicks on the AWS Management Console, you can launch a serverless notebook to query data streams and get results in seconds. Amazon Managed Service for Apache Flink reduces the complexity of building and managing Apache Flink applications. Apache Flink is an open-source framework and engine for processing data streams. It’s highly available and scalable, delivering high throughput and low latency for stream processing applications.
If you’re running Apache Flink workloads, you may experience the non-trivial challenge of developing your distributed stream processing applications without having true visibility into the steps your application performs for data processing. Amazon Managed Service for Apache Flink Studio combines the ease of use of Apache Zeppelin notebooks with the power of the Apache Flink processing engine to provide advanced streaming analytics capabilities in a fully managed offering. This accelerates developing and running stream processing applications that continuously generate real-time insights.
In this post, we introduce you to Amazon Managed Service for Apache Flink Studio and how to get started querying data interactively from an Amazon Managed Streaming for Kafka (Amazon MSK) cluster using SQL, Python, and Scala. We also demonstrate how to query data across different topics using Amazon Managed Service for Apache Flink Studio. Amazon Managed Service for Apache Flink Studio is also compatible with Amazon Kinesis Data Streams, Amazon Simple Storage Service (Amazon S3), and a variety of other data sources supported by Apache Flink.
Prerequisites
To get started, you must have the following prerequisites:
- An MSK cluster
- A data generator for populating data into the MSK cluster
To follow this guide and interact with your streaming data, you need a data stream with data flowing through.
Create and set up a Kafka cluster
You can create your Kafka cluster either using the Amazon MSK console or the following AWS Command Line Interface (AWS CLI) command. For console instructions, see Getting Started Using Amazon MSK and creating Studio notebook with MSK
You can either create topics and messages or use existing topics in the MSK cluster.
For this post, we have two topics in the MSK cluster, impressions and clicks, and they have the following fields in JSON format:
- impressions –
bid_id,campaign_id,country_code,creative_details,i_timestamp - clicks –
correlation_id,tracker,c_timestamp
The correlation_id is the click correlation ID for a bid_id, so the field has common values across topics that we use for the join.
For the data in the MSK topic, we use the Amazon MSK Data Generator. Refer to the GitHub repo for setup and usage details. (We will be using the adtech.json sample for this blog)
The following are sample JSON records generated for the impressions topic:
The following are sample JSON records generated for the clicks topic:
Create a Kinesis Data Analytics Studio notebook
You can start interacting with your data stream by following these simple steps:
- On the Amazon MSK console, choose Process data in real time.
- Choose Apache Flink – Studio Notebook.
- Enter the name of your Amazon Managed Service for Apache Flink Studio notebook and allow the notebook to create an AWS Identity and Access Management (IAM) role.
You can create a custom role for specific use cases on the IAM console.
- Choose an AWS Glue database to store the metadata around your sources and destinations, which the notebook uses.
- Choose Create Studio notebook.
We keep the default settings for the application and can scale up as needed.
- After you create the application, choose Start to start the Apache Flink application.
- When it’s complete (after a few minutes), choose Open in Apache Zeppelin.
To connect to an MSK cluster, you must specify the same VPC, subnets, and security groups for the Amazon Managed Service for Apache Flink Studio notebook as were used to create the MSK cluster. If you chose Process data in real time during your setup, this is already set for you.
The Studio notebook is created with an IAM role for the notebook that grants the necessary access for the AWS Glue Data Catalog and tables.
Example applications
Apache Zeppelin supports the Apache Flink interpreter and allows for the use of Apache Flink directly within Zeppelin for interactive data analysis. Within the Flink interpreter, three languages are supported as of this writing: Scala, Python (PyFlink), and SQL. The notebook requires a specification to one of these languages at the top of each paragraph in order to interpret the language properly:
There are several other predefined variables per interpreter, such as the senv variable in Scala for a StreamExecutionEnvironment, or st_env in Python for the same. You can review the full list of these entry point variables.
In this section, we show the same example code in all three languages to highlight the flexibility Zeppelin affords you for development.
SQL
We use the %flink.ssql(type=update) header to signify to the notebook that this paragraph will be interpreted as Flink SQL. We create two tables from the Kafka topics:
- impressions – With
bid_id,campaign_id,creative_details,country_code, andi_timestampcolumns providing details of impressions in the system - clicks – With
correlation_id,tracker, andc_timestampproviding details of the clicks for an impression.
The tables use the Kafka connector to read from a Kafka topic called impressions and clicks in the us-east-1 Region from the latest offset.
As soon as this statement runs within a Zeppelin notebook, AWS Glue Data Catalog tables are created according to the declaration specified in the create statement, and the tables are available immediately for queries from the MSK cluster.
You don’t need to complete this step if your AWS Glue Data Catalog already contains the tables.
The following screenshot is the AWS Glue Data Catalog view, which shows the tables that represent MSK topics.
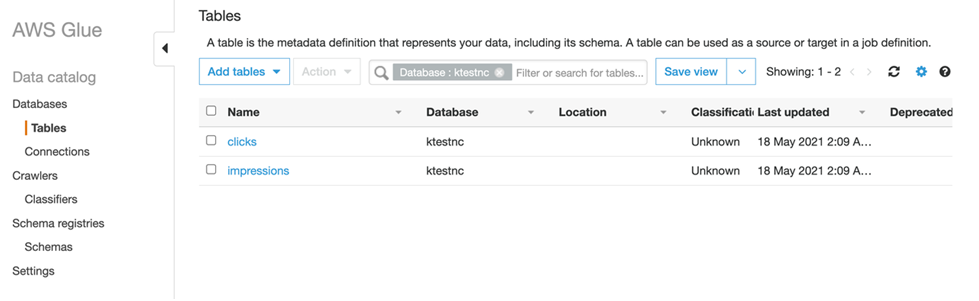
In the preceding tables, WATERMARK FOR serve_time AS serve_time - INTERVAL '5' SECOND means that we can tolerate out-of-order delivery of events in the timeframe of 5 seconds and still produce correct results.
After you create the tables, run a query that calculates the number of impressions within a tumbling window of 60 seconds broken down by campaign_id and creative_details:
The results from this query appear as soon as results are available.

Additionally, we want to see the clickthrough rate of the impressions:
This query produces one row for each impression and matches it with a click (if any) that was observed within 2 minutes after serving the ad. This is essentially performing a join operation across the topics to get this information.

You can insert this data back into an existing Kafka topic using the following code:
Create the corresponding table for the Kafka topic in the Data Catalog if it doesn’t exist already. After you run the preceding query, you can see data in your Amazon MSK topic (see the following sample below):
This is the CSV data from the preceding query, which shows the ClickThroughRate for the impressions. You can use this mechanism to store data back persistently into Kafka from Flink directly.
Scala
We use the %flink header to signify that this code block will be interpreted via the Scala Flink interpreter, and create a table identical to the one from the SQL example. However, in this example, we use the Scala interpreter’s built-in streaming table environment variable, stenv, to run a SQL DDL statement. If the table already exists in the AWS Glue Data Catalog, this statement issues an error stating that the table already exists.
Performing a tumbling window in the Scala table API first requires the definition of an in-memory reference to the table we created. We use the stenv variable to define this table using the from function and referencing the table name. After this is created, we can create a windowed aggregation over 1 minute of data, serve_time column. See the following code:
Use the ZeppelinContext to visualize the Scala table aggregation within the notebook:
The following screenshot shows our results.


Additionally, we want to see the clickthrough rate of the impressions by joining with the clicks:
Use the ZeppelinContext to visualize the Scala table aggregation within the notebook.
The following screenshot shows our results.


Python
We use the %flink.pyflink header to signify that this code block will be interpreted via the Python Flink interpreter, and create a table identical to the one from the SQL and Scala examples. In this example, we use the Python interpreter’s built-in streaming table environment variable, st_env, to run a SQL DDL statement. If the table already exists in the AWS Glue Data Catalog, this statement issues an error stating that the table already exists.
Performing a sliding (hopping) window in the Python table API first requires the definition of an in-memory reference to the table we created. We use the st_env variable to define this table using the from_path function and referencing the table name. After this is created, we can create a windowed aggregation over 1 minute of data, emitting results every 5 seconds according to the event_time column. See the following code:
Use the ZeppelinContext to visualize the Python table aggregation within the notebook:
The following screenshot shows our results.

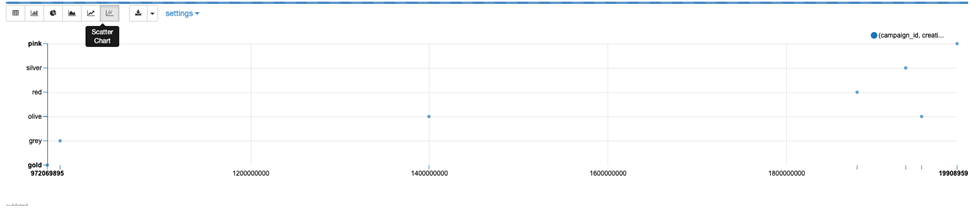
Additionally, we want to see the clickthrough rate of the impressions by joining with the clicks:
Scaling
A Studio notebook consists of one or more tasks. You can split a Studio notebook task into several parallel instances to run, where each parallel instance processes a subset of the task’s data. The number of parallel instances of a task is called its parallelism, and adjusting that helps run your tasks more efficiently.
On creation, Studio notebooks are given four parallel Kinesis Processing Units (KPUs), which make up the application parallelism. To increase that parallelism, navigate to the Amazon Managed Service for Apache Flink console, choose your application name, and choose the Configuration tab.

From this page, in the Scaling section, choose Edit and modify the Parallelism entry. We don’t recommend increasing the Parallelism Per KPU setting higher than 1 unless your application is I/O bound.
Choose Save changes to increase or decrease your application’s parallelism.
Clean up
You may want to clean up the demo environment when you are done, To do so, stop the Studio notebook and delete the resources created for the Data Generator and the Amazon MSK cluster ( if you created a new cluster).
Summary
Amazon Managed Service for Apache Flink Studio makes developing stream processing applications using Apache Flink much faster, with rich visualizations, a scalable and user-friendly interface to develop pipelines, and the flexibility of language choice to make any streaming workload performant and powerful. You can run paragraphs from within the notebook or promote your Studio notebook to a Amazon Managed Service for Apache Flink application with a durable state, as shown in the SQL example in this post.
For more information, see the following resources:
- Amazon Managed Service for Apache Flink features
- Using a Studio notebook with Amazon Managed Service for Apache Flink
About the Author
 Chinmayi Narasimhadevara is a Solutions Architect focused on Big Data and Analytics at Amazon Web Services. Chinmayi has over 15 years of experience in information technology. She helps AWS customers build advanced, highly scalable and performant solutions
Chinmayi Narasimhadevara is a Solutions Architect focused on Big Data and Analytics at Amazon Web Services. Chinmayi has over 15 years of experience in information technology. She helps AWS customers build advanced, highly scalable and performant solutions