AWS Machine Learning Blog
Build machine learning at the edge applications using Amazon SageMaker Edge Manager and AWS IoT Greengrass V2
Running machine learning (ML) models at the edge can be a powerful enhancement for Internet of Things (IoT) solutions that must perform inference without a constant connection back to the cloud. Although there are numerous ways to train ML models for countless applications, effectively optimizing and deploying these models for IoT devices can present many obstacles.
Some popular questions include: How can ML models be packaged for deployment across a fleet of devices? How can an ML model be optimized for specific edge device hardware? How can we efficiently get inference feedback back to the cloud? What ML libraries do we need to install on our storage-constrained IoT devices?
In this post, we show how you can integrate Amazon SageMaker Edge Manager and AWS IoT Greengrass to build robust ML applications that are targeted specifically for edge use cases. AWS IoT Greengrass is an open-source edge runtime that we can use to build, deploy, and manage edge applications across a fleet of devices. Edge Manager can optimize and package our ML models for specific device targets, and provides an integration capability for inference in edge applications via gRPC.
Solution overview
We take a use case in the agriculture industry as an example. Today’s agriculture customers are looking for solutions to monitor, track, and count livestock in the most remote areas when transferred from the nursery, weaning, growth to finish, and market locations. These solutions must be run at the edge for connectivity, latency, and cost reasons. To solve this problem, we show you how to use the Amazon SageMaker built-in object detection model and deploy it on edge devices like NVIDIA Nano, TX2, and Xavier via AWS IoT Greengrass and run inferences on them. You can then use these detections as input to tracking algorithms that help track and monitor animals.
One of the applications of tracking animals is to count them. Counting pigs can be hard; they move quickly, they turn around, they all look the same! Three AWS experts tried to count pigs manually, and all three got different answers. Computer vision and ML at the edge can increase efficiency and accuracy for livestock management. The most important customer benefit is getting consistent, accurate, near-real-time livestock counts to support sound economic decisions such as feed and weight management that can optimize revenue gain or reduce revenue loss. Secondly, reducing or eliminating manual counting tasks allows workers to focus on higher-value tasks such as animal care. This increases operational efficiency and product quality. Apart from the agriculture industry, this has applications in monitoring wildlife as well.
We look at how to set up an edge device, (in this case, a NVIDIA Jetson Xavier) with AWS IoT Greengrass. After we have trained the model, we deploy it to this device. We then run inference at the edge to count how many animals are in a given image. You can feed a live camera stream to the system, where you can use object detection outputs combined with a tracker to count animals in real time. We go over the following sections to take you through creating this application:
- Prepare your dataset.
- Use the Amazon SageMaker built-in object detection model.
- Optimize the model for the edge device.
- Package the model for the edge.
- Deploy the models to the edge.
- Build an AWS IoT Greengrass application for running inference and counting using an AWS Lambda function.
- Set up the edge device.
- Run the application at the edge to perform inference.
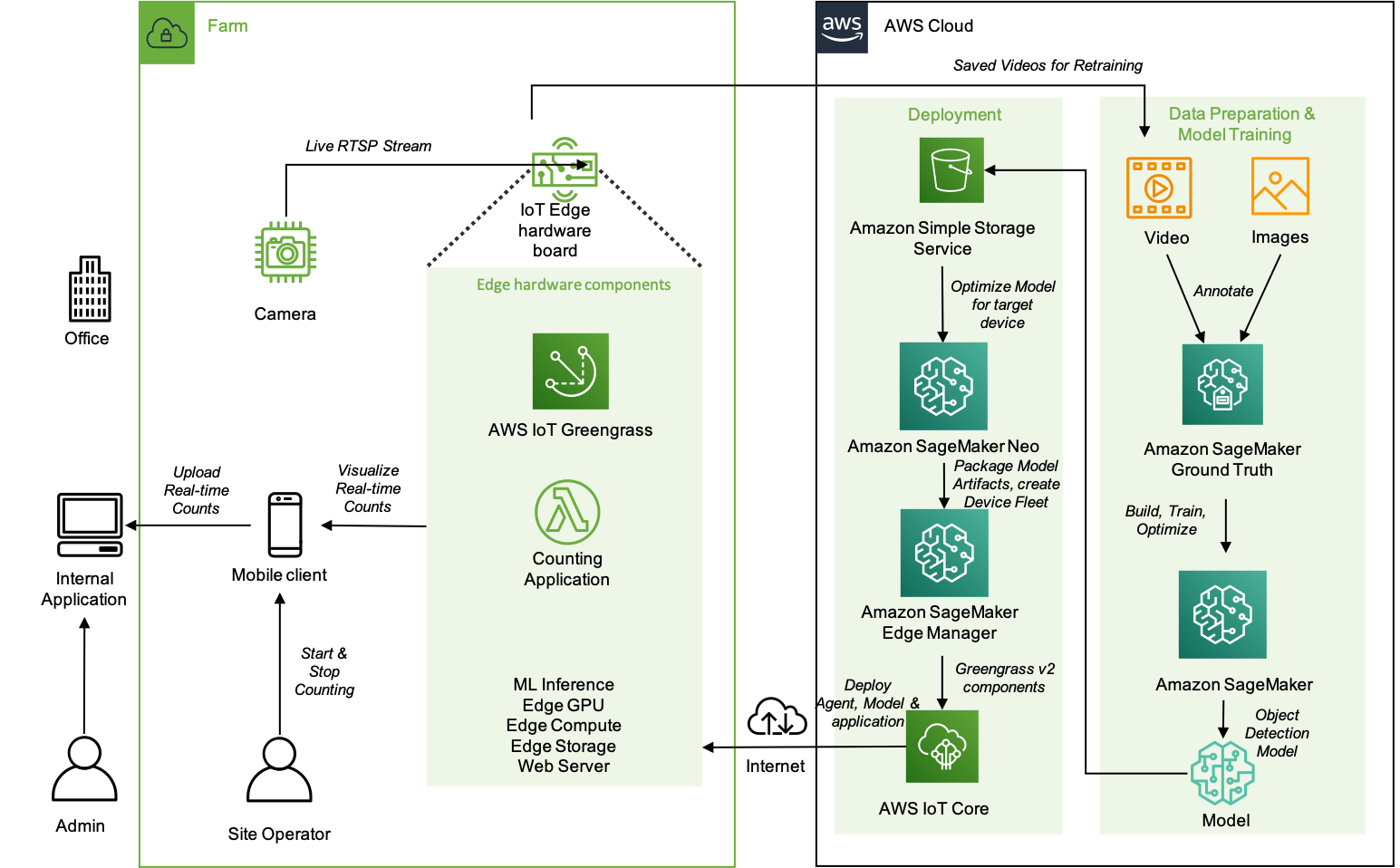
The following diagram shows a high-level architecture of the components that reside on the farm and how they interact with the AWS services in the cloud.
Prepare the dataset
For this post, we gather videos of the livestock from multiple farms with enough lighting and diverse floors. When you collect videos for training your model, use a ceiling-mounted camera that covers the whole alley where the livestock are transferred. Split those videos into frames, and use Amazon SageMaker Ground Truth to create annotations with the help of Amazon Mechanical Turk. The following is an example of an annotated pigs image.

Example notebooks available for dataset creation are on the GitHub repo. You can use data augmentation techniques to increase your dataset for training.
Build a livestock detection model
We use the SageMaker built-in object detection model and train it on a dataset of pigs. One of the biggest challenges in livestock is crowding. To make the model learn such scenes, we recommend experimenting with bounding boxes around the heads instead of entire bodies.
When we have the annotated dataset, we can use the built-in object detection model that uses the Single Shot multibox Detector (SSD) algorithm. The following example notebook illustrates how to do this, and you can pass in your livestock dataset to create an ML model.
Optimize the model for the edge
We use Amazon SageMaker Neo to optimize the model to the target device—in this case, the Jetson Xavier. Neo automatically optimizes ML models for inference on cloud instances and edge devices to run faster with no loss in accuracy. You start with an ML model already built with DarkNet, Keras, MXNet, PyTorch, TensorFlow, TensorFlow-Lite, ONNX, or XGBoost and trained in SageMaker or anywhere else. Then you choose your target hardware platform, which can be a SageMaker hosting instance or an edge device based on processors from Ambarella, Apple, ARM, Intel, MediaTek, Nvidia, NXP, Qualcomm, RockChip, Texas Instruments, or Xilinx. With a single click, Neo optimizes the trained model and compiles it into an executable. The compiler uses an ML model to apply the performance optimizations that extract the best available performance for your model on the cloud instance or edge device. You then deploy the model as a SageMaker endpoint or on supported edge devices and start making predictions.
Package the model for the edge
After you optimize the model for the edge device, we can use Edge Manager to optimize, secure, monitor, and maintain ML models on fleets of smart cameras, robots, personal computers, and mobile devices.
Edge Manager provides a software agent that runs on edge devices. The agent comes with an ML model optimized with Neo automatically, so you don’t need Neo runtime installed on your devices to take advantage of the model optimizations. The agent also can collect prediction data and send a sample of the data to the cloud for monitoring, labeling, and retraining so you can keep models accurate over time. You can view all the data on the Edge Manager dashboard, which reports on the operation of deployed models.
Because Edge Manager enables you to manage models separately from the rest of the application, you can update the model and the application independently, reducing costly downtime and service disruptions. Edge Manager also cryptographically signs your models so you can verify that it wasn’t tampered with as it moves from the cloud to edge devices.
Deploy the models to the edge
You can then deploy the packaged models and their business applications that use these models using AWS IoT Greengrass, an open-source IoT edge runtime and cloud service that lets you quickly and easily build intelligent device software.
AWS IoT Greengrass Version 2 is a new major version release of AWS IoT Greengrass. You can add or remove pre-built software components based on your use cases, configured specifically for your target device’s CPU, GPU, and memory resources. For example, you can choose to include only prebuilt AWS IoT Greengrass components, such as stream manager, when you need to process data streams with your application. When you want to perform ML inference locally on your devices, you can also include ML components, such as the public Edge Manager component provided by AWS, or a custom component containing your ML model. By decoupling your ML model and inference client code, you can quickly swap out different model versions without having to update application code or re-deploy your entire solution. The following GitHub repository shows an example of how to easily deploy an ML model, Edge Manager, and AWS IoT Greengrass Lambda function using AWS IoT Greengrass V2 custom components.
In this example, we deploy three components, as illustrated in the following diagram: the public Edge Manager component, a custom component that contains our Python inference client code, and another custom component wrapping our ML model.
The Edge Manager component downloads, installs, and runs an Edge Manager binary agent specific to our OS and platform architecture. When the agent is running, a gRPC-based service enables clients to manage models through a collection of APIs. With requests to the APIs, the client can load, unload, and describe models; run predictions with raw bytes or a SharedMemoryHandle of a multi-dimensional tensor array; and upload input and output tensors to the cloud. Clients can easily communicate with these APIs using the proto file available as part of the Edge Manager release artifacts.

Build an AWS IoT Greengrass V2 application using a Lambda function
To run your business logic at the edge, we package the code as an AWS IoT Greengrass Lambda function that runs indefinitely on the edge device. For example, the following Lambda function counts the number of livestock in a still image. You can also extend this to do object tracking in videos using tracking algorithms like correlation tracker, CSRT, GOTURN, KCF, and so on. See the following code:
Set up the edge device
For this demonstration, we use an NVIDIA Jetson Xavier NX development kit as our target edge device. To get our device communicating with AWS, we installed AWS IoT Greengrass V2 runtime software over SSH, which doesn’t require the device to have local AWS credentials, or the AWS Command Line Interface (AWS CLI) installed. Another major benefit of AWS IoT Greengrass V2 is that device provisioning to AWS IoT Core is built in.
From our development workstation (which has the AWS CLI installed along with a configured named profile), we can use the provided script to SSH into the target device, install necessary prerequisites (like OpenJDK), download the latest release of AWS IoT Greengrass V2 runtime software, and kick off the AWS IoT Greengrass installer.
The installer first installs the AWS IoT Greengrass nucleus component, the only mandatory component and the minimum requirement to run AWS IoT Greengrass V2 on a device. Next, the installer creates an IoT thing registered as an AWS IoT Core device in AWS IoT Greengrass V2, and subsequently downloads a root CA certificate, private key, and X509 device certificate used to communicate to the AWS Cloud over a TLS connection. The installer then associates the AWS IoT Greengrass Core device to an AWS IoT thing group, a group of AWS IoT things that we use as a target for our AWS IoT Greengrass deployments.
Finally, the installer creates a device role alias and associated AWS Identity and Access Management (IAM) role, which the AWS IoT Greengrass Core device can use to request temporary credentials for accessing permitted AWS resources not accessible through MQTT.
Run inference
After installation is complete on the device, we can configure a deployment of specified components to our target device running the AWS IoT Greengrass V2 runtime software. To try this out, follow the instructions in the README.md. Example code and setup scripts are available in the GitHub repo
Conclusion
In this post, we shared with you an art-of-the-possible computer vision solution that you can build using a combination of AWS services. There is so much potential for using such a solution to improve yield, throughput, unit margin, and customer satisfaction even in other industries like retail, automotive, manufacturing, and supply chain.
If your use case requires or is able to use computer vision in the cloud, check out Amazon Lookout for Vision and Amazon Rekognition Custom Labels. Reach out to us if you have any feedback or want to share how this helped your ML and IoT journey with the help of AWS.
Related resources
To related resources, see the following:
- Edge Manager Agent
- Deploy Model Package and Edge Manager Agent with AWS IoT Greengrass
- Running image classification on an NXP i.MX8MQEVK device
- Running object detection on a Jetson Xavier device
- Running object detection on an EC2 instance
- Inference applications using SageMaker Edge Manager Agent component
- Use Amazon SageMaker Edge Manager on Greengrass core devices
About the Authors
 Pavan Kumar Sunder is a Senior Solutions Architect with the Envision Engineering team at Amazon Web Services. He provides technical guidance and helps customers accelerate their ability to innovate through showing the art of the possible on AWS. He has built multiple prototypes around AI/ML, IoT, and robotics for our customers.
Pavan Kumar Sunder is a Senior Solutions Architect with the Envision Engineering team at Amazon Web Services. He provides technical guidance and helps customers accelerate their ability to innovate through showing the art of the possible on AWS. He has built multiple prototypes around AI/ML, IoT, and robotics for our customers.
 Jon Slominski is a Sr. Prototyping Architect with the Americas Envision Engineering team at AWS. Building prototypes focused on IoT, AI/ML, and robotics, Jon helps customers innovate and envision the art of the possible. Outside of work, Jon enjoys spending time and traveling with his wife and daughters.
Jon Slominski is a Sr. Prototyping Architect with the Americas Envision Engineering team at AWS. Building prototypes focused on IoT, AI/ML, and robotics, Jon helps customers innovate and envision the art of the possible. Outside of work, Jon enjoys spending time and traveling with his wife and daughters.