AWS Machine Learning Blog
Content moderation design patterns with AWS managed AI services
User-generated content (UGC) grows exponentially, as well as the requirements and the cost to keep content and online communities safe and compliant. Modern web and mobile platforms fuel businesses and drive user engagement through social features, from startups to large organizations. Online community members expect safe and inclusive experiences where they can freely consume and contribute images, videos, text, and audio. The ever-increasing volume, variety, and complexity of UGC make traditional human moderation workflows challenging to scale to protect users. These limitations force customers into inefficient, expensive, and reactive mitigation processes that carry an unnecessary risk for users and the business. The result is a poor, harmful, and non-inclusive community experience that disengages users, negatively impacting community, and business objectives.
The solution is scalable content moderation workflows that rely on artificial intelligence (AI), machine learning (ML), deep learning (DL), and natural language processing (NLP) technologies. These constructs translate, transcribe, recognize, detect, mask, redact, and strategically bring human talent into the moderation workflow, to run the actions needed to keep users safe and engaged while increasing accuracy and process efficiency, and lowering operational costs.
This post reviews how to build content moderation workflows using AWS AI services. To learn more about business needs, impact, and cost reductions that automated content moderation brings to social media, gaming, e-commerce, and advertising industries, see Utilize AWS AI services to automate content moderation and compliance.
Solution overview
You don’t need expertise in ML to implement these workflows and can tailor these patterns to your specific business needs! AWS delivers these capabilities through fully managed services that remove operational complexity and undifferentiated heavy lifting, and without a data science team.
In this post, we demonstrate how to efficiently moderate spaces where customers discuss and review products using text, audio, images, video, and even PDF files. The following diagram illustrates the solution architecture.

Prerequisites
By default, these patterns demonstrate a serverless methodology, where you only pay for what you use. You continue paying for the compute resources, such as AWS Fargate containers, and storage, such as Amazon Simple Storage Service (Amazon S3), until you delete those resources. The discussed AWS AI services also follow a consumption pricing model per operation.
Non-production environments can test each of these patterns within the Free Tier, assuming your account’s eligibility.
Moderate plain text
First, you need to implement content moderation for plain text. This procedure serves as the foundation for more sophisticated media types and entails two high-level steps:
- Translate the text.
- Analyze the text.
Global customers want to collaborate with social platforms in their native language. Meeting this expectation can add complexity because design teams must construct a workflow or steps for each language. Instead, you can use Amazon Translate to convert text to over 70 languages and variants in over 15 regions. This capability enables you to write analysis rules for a single language and apply those rules across the global online community.
Amazon Translate is a neural machine translation service that delivers fast, high-quality, affordable, and customizable language translation. You can integrate it into your workflows to detect the dominant language and translate the text. The following diagram illustrates the workflow.
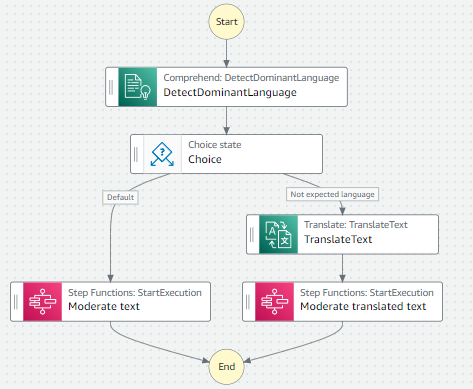
The APIs operate as follows:
- The DetectDominantLanguage API determines the dominant language of the input text. For a list of languages that Amazon Comprehend can detect, see Dominant language.
- The TranslateText API translates input text from the source language to the target language with optional profanity masking. For a list of available languages and language codes, see Supported languages and language codes.
- The StartExecution and StartSyncExecution APIs start an AWS Step Functions state machine.
Next, you can use NLP to uncover connections in text, like discovering key phrases, analyzing sentiment, and detecting personally identifiable information (PII). Amazon Comprehend APIs extract those valuable insights and pass them into custom function handlers.
Running those handlers inside AWS Lambda functions elastically scales your code without thinking about servers or clusters. Alternatively, you can process insights from Amazon Comprehend with microservices architecture patterns. Regardless of the runtime, your code focuses on using the results, not parsing text.
The following diagram illustrates the workflow.
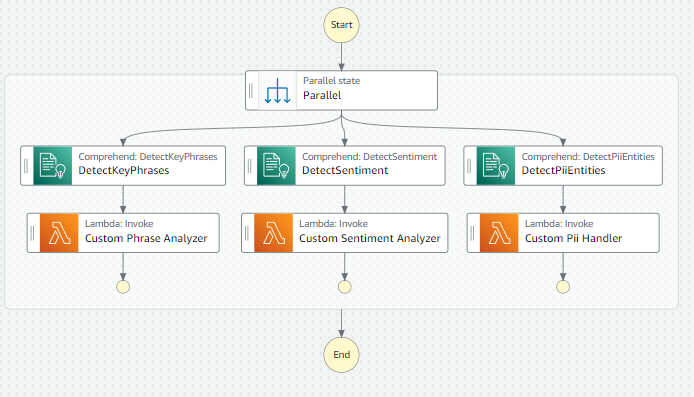
Lambda functions interact with the following APIs:
- The DetectEntities API discovers and groups the names of real-world objects such as people and places in the text. You can use a custom vocabulary to redact inappropriate and business-specific entity types.
- The DetectSentiment API identifies the overall sentiment of the text as positive, negative, or neutral. You can train custom classifiers to recognize the industry-specific situations of interest and extract the text’s conceptual meaning.
- The DetectPIIEntities API identifies PII in your text, such as address, bank account number, or phone number. The output contains the type of PII entity and its corresponding location.
Moderate audio files
To moderate audio files, you must transcribe the file to text and then analyze it. This process has two variants depending on whether you’re processing individual files (synchronous) or live audio streams (asynchronous). Synchronous workflows are ideal for batch processing, with the caller receiving one complete response. In contrast, audio streams require periodic sampling with multiple transcription results.
Amazon Transcribe is an automatic speech recognition service that uses ML models to convert audio to text. You can integrate it into synchronous workflows by starting a transcription job and periodically querying the job’s status. After the job is complete, you can analyze the output using the plain text moderation workflow from the previous step.
The following diagram illustrates the workflow.
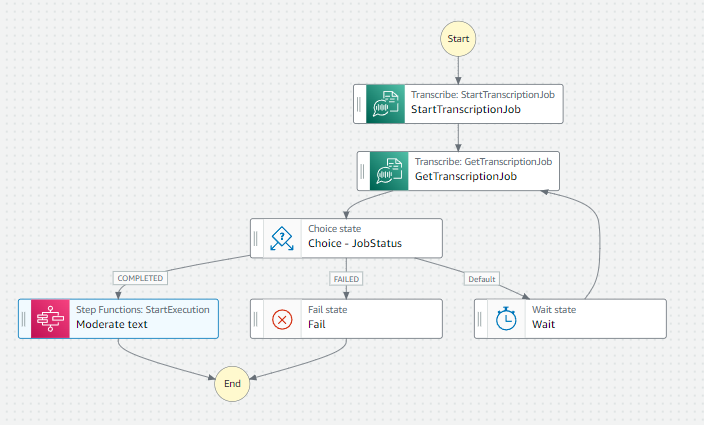
The APIs operate as follows:
- The StartTranscriptionJob API starts an asynchronous job to transcribe speech to text.
- The GetTranscriptionJob API returns information about a transcription job. To see the status of the job, check the
TranscriptionJobStatusfield. If the status property isCOMPLETED, you can find the results at the location specified in theTranscriptFileUrifield. If you enable content redaction, the redacted transcript appears inRedactedTranscriptFileUri.
Live audio streams need a different pattern that supports a real-time delivery model. Streaming can include pre-recorded media, such as movies, music, and podcasts, and real-time media, such as live news broadcasts. You can transcribe audio chunks instantaneously using Amazon Transcribe streaming over HTTP/2 and WebSockets protocols. After posting a chunk to the service, you receive one or more transcription result objects describing the partial and complete transcription segments. Segments that require moderation can reuse the plain text workflow from the previous section. The following diagram illustrates this process.
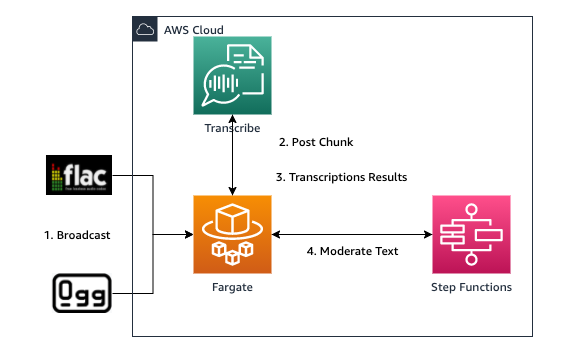
The StartStreamingTranscription API starts a bidirectional HTTP/2 stream where audio streams to Amazon Transcribe, streaming the transcription results to your application.
Moderate images and photos
Moderating images requires detecting inappropriate, unwanted, or offensive content containing nudity, suggestiveness, violence, and other categories from images and photos content.
Amazon Rekognition enables you to streamline or automate your image and video moderation workflows without requiring ML expertise. Amazon Rekognition returns a hierarchical taxonomy of moderation-related labels. This information makes it easy to define granular business rules per your standards and practices, user safety, and compliance guidelines. ML experience is not required to use these capabilities. Amazon Rekognition can detect and read the text in an image and return bounding boxes for each word found. Amazon Rekognition supports text detection written in English, Arabic, Russian, German, French, Italian, Portuguese, and Spanish!
You can use the machine predictions to automate specific moderation tasks entirely. This capability enables human moderators to focus on higher-order work. In addition, Amazon Rekognition can quickly review millions of images or thousands of videos using ML and flag the subset of assets requiring further action. Prefiltering helps provide comprehensive yet cost-effective moderation coverage while reducing the amount of content that human teams moderate.
The following diagram illustrates the workflow.

The APIs operate as follows:
- The DetectModerationLabels API detects unsafe content in specified JPEG or PNG formatted images. Use DetectModerationLabels to moderate pictures depending on your requirements. For example, you might want to filter images that contain nudity but not images containing suggestive content.
- The DetectText API detects text in the input image and converts it into machine-readable text.
Moderate rich text documents
Next, you can use Amazon Textract to extract handwritten text and data from scanned documents. This process begins with invoking the StartDocumentAnalysis action to parse Microsoft Word and Adobe PDF files. You can monitor the job’s progress with the GetDocumentAnalysis action.
The analysis result specifies each uncovered page, paragraph, table, and key-value pair in the document. For example, suppose a health provider must mask patient names in only the claim description field. In that case, the analysis report can power intelligent document processing pipelines that moderate and redact the specific data field. The following diagram illustrates the pipeline.

The APIs operate as follows:
- The StartDocumentAnalysis API starts the asynchronous analysis of an input document for relationships between detected items such as key-value pairs, tables, and selection elements
- The GetDocumentAnalysis API gets the results for an Amazon Textract asynchronous operation that analyzes text in a document
Moderate videos
A standard approach to video content moderation is through a frame sampling procedure. Many use cases don’t need to check every frame, and selecting one every 15–30 seconds is sufficient. Sampled video frames can reuse the state machine to moderate images from the previous section. Similarly, the existing process to moderate audio can support the file’s audible content. The following diagram illustrates this workflow.
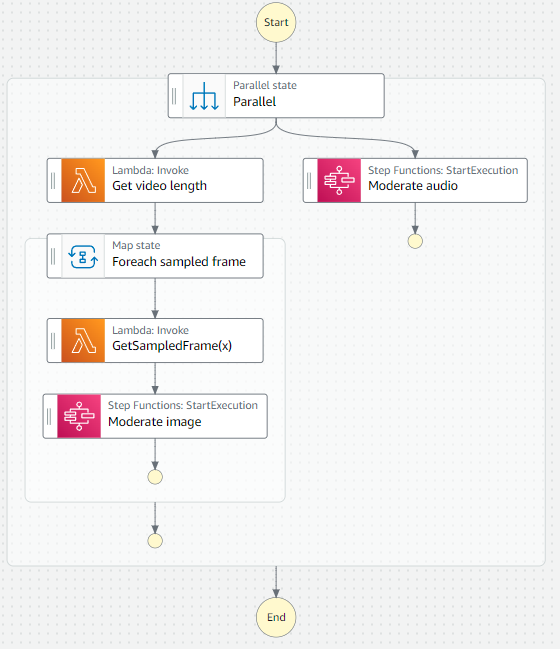
The Invoke API runs a Lambda function and synchronously waits for the response.
Suppose the media file is an entire movie with multiple scenes. In that case, you can use the Amazon Rekognition Segment API, a composite API for detecting technical cues or shot detection. Next, you can use these time offsets to parallel process each segment with the previous video moderation pattern, as shown in the following diagram.

The APIs operate as follows:
- The StartSegmentationDetection API starts asynchronous detection of segment detection in a stored video
- The GetSegmentationDetection API gets the segment detection results of an Amazon Rekognition Video analysis started by the StartSegmentDetection API
Extracting individual frames from the movie doesn’t require fetching the object from Amazon S3 multiple times. A naïve solution involves reading the video into memory and paginating to the end. This pattern is ideal for short clips and where assessments aren’t time-sensitive.
Another strategy entails moving the file once to Amazon Elastic File System (Amazon EFS), a fully managed, scalable, shared file system for other AWS services, such as Lambda. With Amazon EFS for Lambda, you can efficiently distribute data across function invocations. Each invocation efficiently handles a small chunk, unlocking the potential for massively parallel processing and faster processing times.
Clean up
After you experiment with the methods in this post, you should delete any content in S3 buckets to avoid future costs. If you implemented these patterns with provisioned compute resources like Amazon Elastic Compute Cloud (Amazon EC2) or Amazon Elastic Container Service (Amazon ECS), you should stop those instances to avoid further charges.
Conclusion
User-generated content and its value to gaming, social media, ecommerce, and financial and health services organizations will continue to grow. Still, startups and large organizations need to create efficient moderation processes to protect users, information, and the business, while lowering operational costs. This solution demonstrates how AI, ML, and NLP technologies can efficiently help you moderate content at scale. You can customize AWS AI services to address your specific moderation needs! These fully managed capabilities remove operational complexities. That flexibility strategically integrates contextual insights and human talent into your moderation processes.
For additional information, resources, and to get started for free today, visit the AWS content moderation homepage.
About the Authors
 Nate Bachmeier is an AWS Senior Solutions Architect that nomadically explores New York, one cloud integration at a time. He specializes in migrating and modernizing applications. Besides this, Nate is a full-time student and has two kids.
Nate Bachmeier is an AWS Senior Solutions Architect that nomadically explores New York, one cloud integration at a time. He specializes in migrating and modernizing applications. Besides this, Nate is a full-time student and has two kids.
 Ram Pathangi is a Solutions Architect at Amazon Web Services in the San Francisco Bay Area. He has helped customers in agriculture, insurance, banking, retail, healthcare and life sciences, hospitality, and hi-tech verticals run their businesses successfully on the AWS Cloud. He specializes in databases, analytics, and machine learning.
Ram Pathangi is a Solutions Architect at Amazon Web Services in the San Francisco Bay Area. He has helped customers in agriculture, insurance, banking, retail, healthcare and life sciences, hospitality, and hi-tech verticals run their businesses successfully on the AWS Cloud. He specializes in databases, analytics, and machine learning.
 Roop Bains is a Solutions Architect at AWS focusing on AI/ML. He is passionate about helping customers innovate and achieve their business objectives using artificial intelligence and machine learning. In his spare time, Roop enjoys reading and hiking.
Roop Bains is a Solutions Architect at AWS focusing on AI/ML. He is passionate about helping customers innovate and achieve their business objectives using artificial intelligence and machine learning. In his spare time, Roop enjoys reading and hiking.