



关系数据库和非关系数据库有什么区别?
关系数据库和非关系数据库是应用程序的两种数据存储方法。关系数据库(或 SQL 数据库)以包含行和列的表格格式存储数据。列包含数据属性,行包含数据值。您可以链接关系数据库中的表,以更深入地了解不同数据点之间的相互关系。另一方面,非关系数据库(或 NoSQL 数据库)使用各种数据模型来访问和管理数据。这些数据库专门针对需要大数据量、低延迟和灵活数据模型的应用程序进行了优化,这是通过放宽其他数据库的某些数据一致性限制来实现的。
关系数据库如何存储数据?
关系数据库将数据存储在包含列和行的表中。每列代表一个特定的数据属性,每行代表该数据的一个实例。
您为每个表指定一个主键,即唯一标识表的标识符列。您可以使用主键在表之间建立关系。您可以使用它作为领个表中的外键,在两个表的行之间建立关联。
连接两个表后,可以通过单个查询从这两个表中获取数据。您需要编写 SQL 查询以与关系数据库进行交互。
存储数据的示例
例如,假设一家零售商创建了一张包含所有产品的表。在此表中,您可以为产品名称、描述和价格设置列。另一张表包含有关客户、客户姓名以及客户所购商品的数据。
下表演示了这种方法。
| Product_id(主键) |
Product_name |
Product_cost |
| P1 |
Product_A |
100 USD |
| P2 |
Product_B |
50 USD |
| P3 |
Product_C |
80 USD |
| Customer_id |
Customer_name |
Item_purchased(外键) |
| C1 |
Customer_A |
P2 |
| C2 |
Customer_B |
P1 |
| C3 |
Customer_C |
P3 |
非关系数据库如何存储数据?
由于管理和存储无架构数据的方式不同,因此存在几种不同的非关系数据库系统。无架构数据是指在不受关系数据库要求的限制的情况下存储的数据。
接下来,我们来解释一些常见的非关系数据库类型。
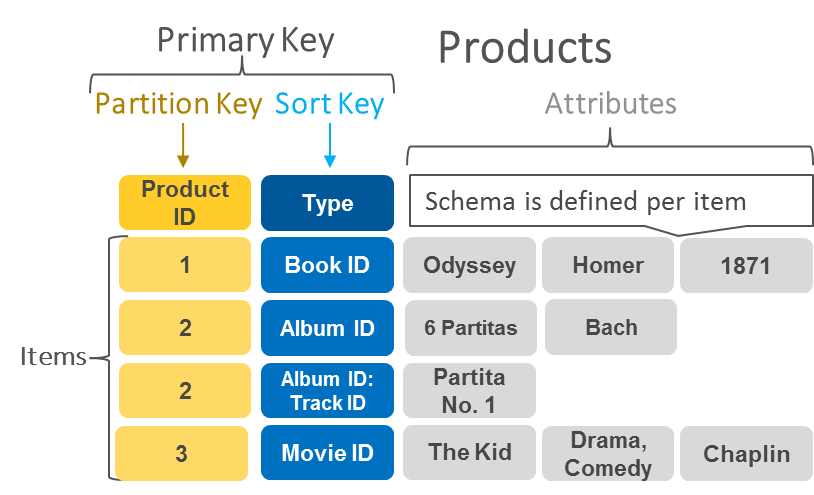
键值数据库
键值数据库将数据存储为键值对的集合。在一个键值对中,键用作唯一标识符。键和值都可以是从简单对象到复杂复合对象的任何内容。
文档数据库
面向文档的数据库的文档模型格式与开发人员在其应用程序代码中使用的格式相同。它们将数据存储为 JSON 对象,这些对象具有灵活、半结构化和分层的性质。
文档数据库中存储的数据如以下示例所示。
| { company_name: "AnyCompany", address: {street: "1212 Main Street", city: "Anytown"}, phone_number: "1-800-555-0101", industry: ["food processing", "appliances"] type: "private", number_of_employees: 987 } |
图形数据库
图形数据库专门用于存储和导航关系。它们使用节点来存储数据实体,并使用边缘来存储实体之间的关系。
边缘总是有起始节点、终止节点、类型和方向。例如,它可以描述父子关系、操作和所有权。

主要区别:关系数据库与非关系数据库
关系数据库和非关系数据库存储和管理数据的方法截然不同。以下各节讨论了两者的具体差异。
结构
关系数据库以表格形式存储数据,并遵循有关数据变体和表关系的严格规则。它们允许您处理对结构化数据的复杂查询,同时保持数据的完整性和一致性。
非关系数据库则更加灵活,适用于需求不断变化的数据。您可以使用它们来存储图像、视频、文档以及其他半结构化和非结构化内容。
数据完整性机制
原子性、一致性、隔离性和持久性(ACID)是指数据库在数据处理中出现错误或中断的情况下保持数据完整性的能力。
关系数据库模型遵循严格的 ACID 属性。这意味着一组后续操作将始终一起完成。如果单个操作失败,则整组操作都会失败。这样可以始终保证数据的准确性。
相比之下,非关系数据库提供了一种更灵活的模型,即基本可用、软状态和最终一致性(BASE)。
非关系数据库可以保证可用性,但不能保证即时一致性。数据库状态可能会随着时间的推移而发生变化,并最终保持一致。一些非关系数据库可能会在性能或其他方面做出妥协,以实现 ACID 合规性。
性能
关系数据库的性能取决于其磁盘子系统。要提高数据库性能,您可以使用 SSD 并通过使用独立磁盘冗余阵列(RAID)配置磁盘来优化磁盘。要获得最佳性能,还必须优化索引、表结构和查询。
相比之下,NoSQL 数据库的性能取决于网络延迟、硬件集群大小和调用应用程序。有几种方法可以提高非关系数据库的性能:
- 增加集群大小
- 最大限度减少网络延迟
- 索引和缓存
与关系数据库相比,NoSQL 数据库为特定应用场景提供更高的性能和可扩展性。
扩展
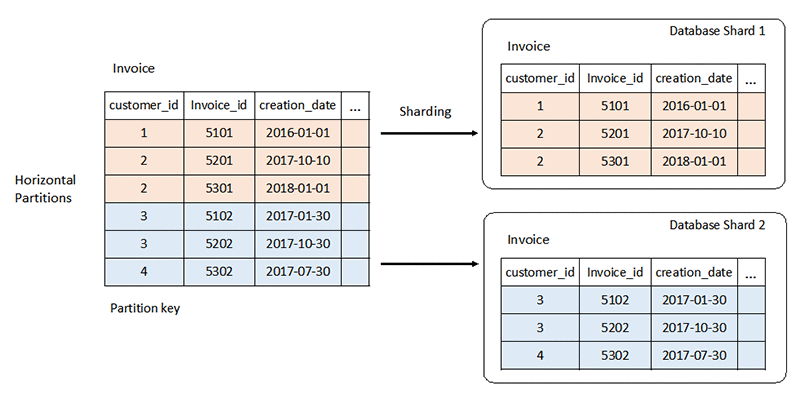
关系数据库系统的严格架构可能会在扩展时带来挑战。通常,您可以通过向服务器添加更多 CPU 或 RAM 资源来进行垂直扩展。您还可以通过跨服务器复制只读工作负载的数据来横向扩展。但是,读写工作负载的横向扩展需要特殊的策略,例如分区和分片。
相比之下,NoSQL 数据库高度可扩展。您可以更轻松地将这类数据库的工作负载分配到多个节点上。这些数据库可以处理大量数据,方法是这些数据分成较小的集,然后将这些集分布在多个节点上。

何时使用关系数据库与非关系数据库
如果您的数据的大小、结构和访问频率可预测,则关系数据库是最佳选择。如果实体之间的关系很重要,您可能还会更愿意使用关系数据库管理系统。例如,如果您有一个结构和关系复杂的大型数据集,您会希望突出这些关系以便分析和使用。
相比之下,非关系模型更适合存储形状或大小比较灵活,或者将来可能发生变化的数据。
此外,在某些情况下,数据关系不太适合表格主键和外键格式。例如,要对社交媒体网络中的好友和关系进行建模,您需要一个在关系数据库中包含数百行的表。
相比之下,这在非关系数据库中可以用单行表示。以下示例显示了在非关系数据库中有四个好友的成员的数据条目。
| Member_id Friend_id M1 M2 M1 M3 M1 M4 M1 M5 |
{member name: “member 1” member friends: “member 2, member 3, member 4, member 5”} |
差异摘要:关系数据库与非关系数据库
| 类别 |
关系数据库 |
非关系数据库 |
| 数据模型 |
表格式。 |
键值、文档或图形。 |
| 数据类型 |
结构化。 |
结构化、半结构化和非结构化。 |
| 数据完整性 |
高,完全符合 ACID 标准。 |
最终一致性模型。 |
| 性能 |
经过改进,向服务器添加更多资源。 |
经过改进,添加了更多服务器节点。 |
| 扩展 |
横向扩展需要额外的数据管理策略。 |
横向扩展很简单。 |
AWS 如何满足您的关系和非关系数据库需求?
Amazon Web Services(AWS)提供多项满足关系和非关系数据库需求的服务。
适用于关系数据库的 AWS 服务
Amazon Relational Database Service(Amazon RDS)是一个托管式服务的集合,可以简化在云中设置、运营和扩展关系数据库的过程。云数据库具有许多优势,例如性能、规模和成本效益。您可以按如下方式使用关系数据库引擎:
- 使用 Amazon RDS for SQL Server 部署多个版本的 SQL Server(2014、2016、2017 和 2019)
- 使用 Amazon RDS for MySQL 支持 MySQL 社区版 5.7 和 8.0。
- 使用 Amazon RDS for MariaDB 支持 MariaDB Server 版 10.3、10.4、10.5 和 10.6
此外,Amazon RDS for Oracle 有两种不同的许可模式,这意味着如果您没有 Oracle 许可证,无需单独购买。
适用于非关系数据库的 AWS 服务
AWS 还提供多项 NoSQL 数据库服务,可满足您的所有 NoSQL 需求。下面是一些示例:
- Amazon DynamoDB 是一项键值数据库服务,可以为任何规模的工作负载提供一致且延迟低于 10 毫秒的性能。
- Amazon DocumentDB(与 MongoDB 兼容)是流行的面向文档的数据库,提供强大且直观的 API,可实现灵活的迭代开发。
- Amazon MemoryDB 是一项持久的内存数据库服务。该服务提供微秒级的读写延迟,可提供超快性能。
- Amazon Neptune 是一项完全托管的图形数据库服务,用于构建和运行高性能图形应用程序。
- Amazon OpenSearch Service 专为提供机器生成数据的近实时可视化和分析而构建。
立即创建账户,开始在 AWS 上使用关系和非关系数据库。