使用 Amazon SageMaker Autopilot
自动创建机器学习模型
Amazon SageMaker 是一项完全托管的服务,可以帮助开发人员和数据科学家快速构建、训练和部署机器学习 (ML) 模型。
在本教程中,您无需编写一行代码就可以自动创建机器学习模型! 您可以使用 Amazon SageMaker Autopilot(一种 AutoML 功能)自动创建最佳分类和回归机器学习模型,同时享有完全控制性和可见性。
在本教程中,您将学习如何完成以下各项:
- 创建 AWS 账户
- 设置 Amazon SageMaker Studio 以访问 Amazon SageMaker Autopilot
- 使用 Amazon SageMaker Studio 下载公共数据集
- 使用 Amazon SageMaker Autopilot 创建训练实验
- 了解训练实验的不同阶段
- 基于训练实验识别和部署性能最佳的模型
- 利用您已部署的模型进行预测
在本教程中,您将扮演在银行工作的开发人员的角色。您接到任务,负责开发一种机器学习模型,用来预测客户是否会注册存单 (CD)。您将使用市场营销数据集对该模型进行训练,该数据集包含有关客户人口统计数据、市场营销活动响应情况和外部因素的信息。
| 关于本教程 | |
|---|---|
| 时间 | 10 分钟 |
| 费用 | 低于 10 USD |
| 使用案例 | Machine Learning |
| 产品 | Amazon SageMaker |
| 受众 | 开发人员 |
| 级别 | 新手 |
| 上次更新日期 | 2020 年 5 月 12 日 |
步骤 1.创建 AWS 账户
本操作的成本低于 10 USD。有关更多信息,请参阅 Amazon SageMaker Studio 定价。
第 2 步:设置 Amazon SageMaker Studio
完成以下步骤,载入 Amazon SageMaker Studio,以访问 Amazon SageMaker Autopilot。
注:有关更多信息,请参阅 Amazon SageMaker 文档中的开始使用 Amazon SageMaker Studio。
a.登录到 Amazon SageMaker 控制台。
注:在右上角,确保选择已推出 Amazon SageMaker Studio 的 AWS 区域。有关区域清单,请参阅载入 Amazon SageMaker Studio。


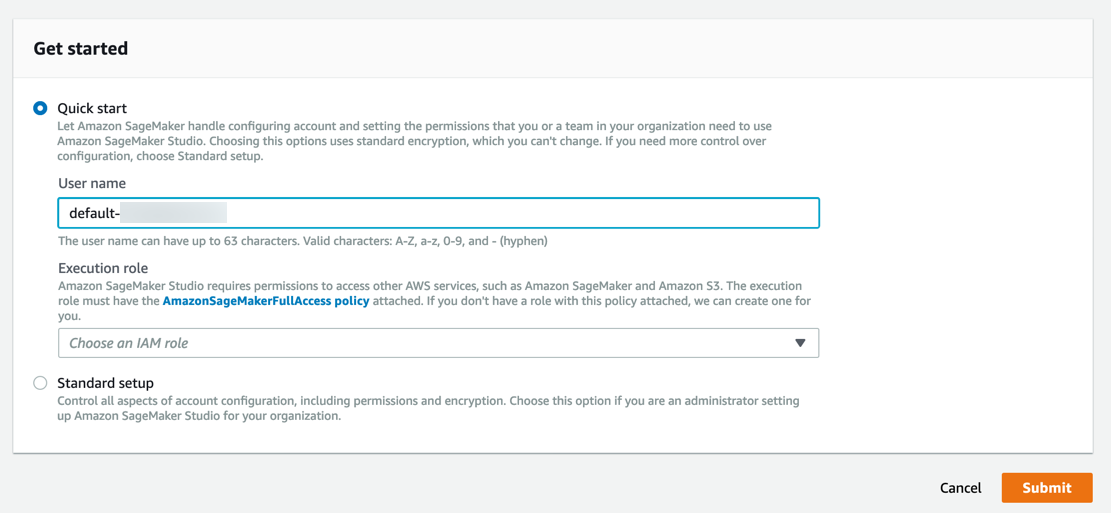
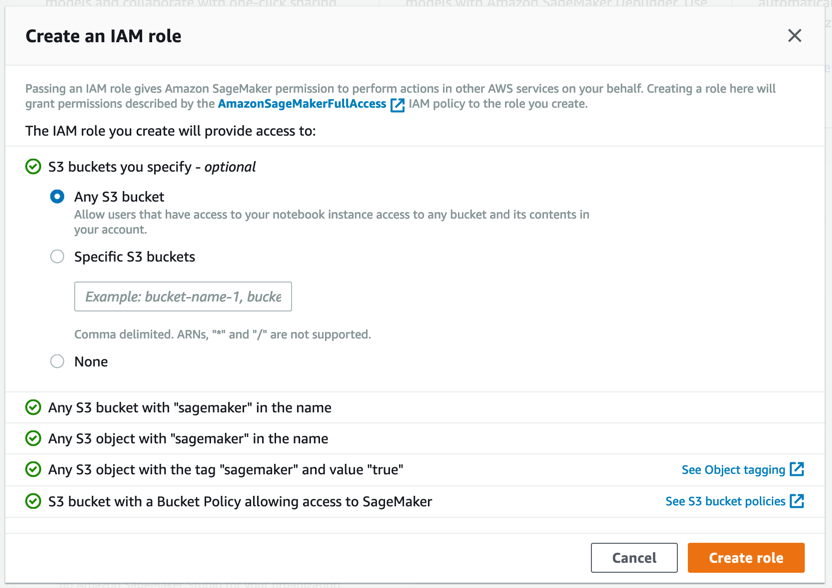
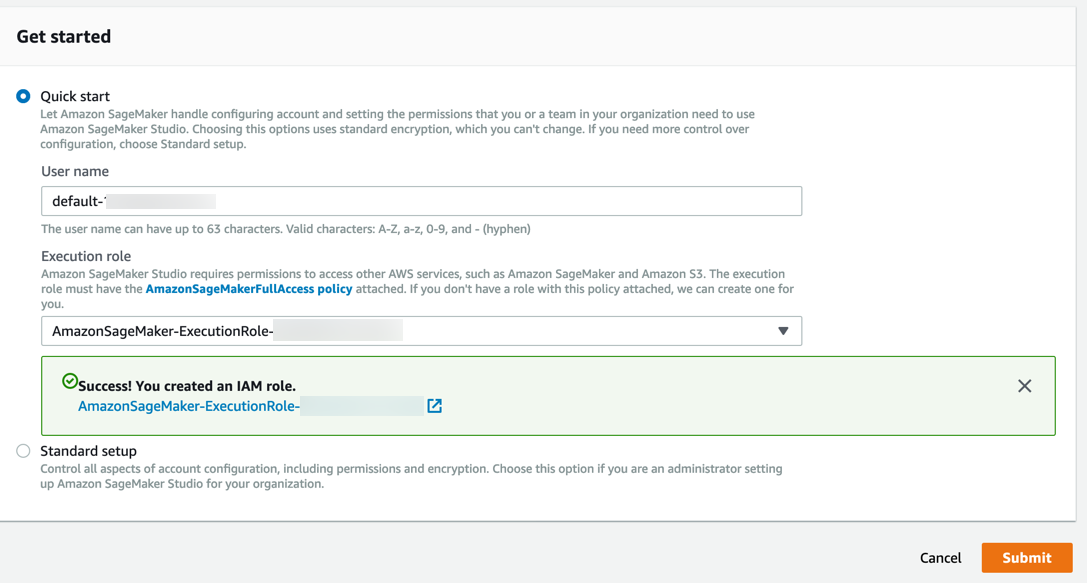
Amazon SageMaker 将创建一个具有所需权限的角色,并将其分配给您的实例。
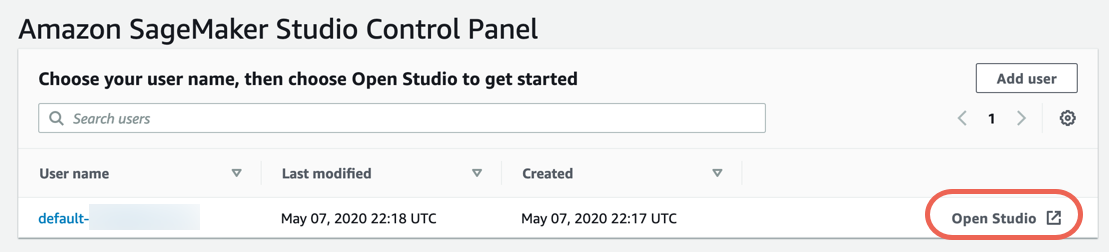
第 3 步:下载数据集
完成以下步骤,下载并浏览数据集。
注:有关更多信息,请参阅 Amazon SageMaker 文档中的 Amazon SageMaker Studio 介绍。
%%sh
apt-get install -y unzip
wget https://sagemaker-sample-data-us-west-2.s3-us-west-2.amazonaws.com/autopilot/direct_marketing/bank-additional.zip
unzip -o bank-additional.zip
d.将以下代码复制并粘贴到新的代码单元格中,然后选择运行。
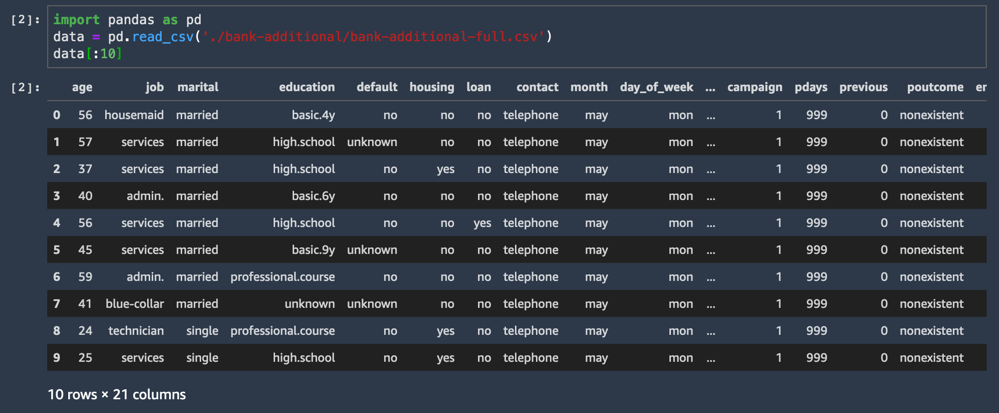
CSV 数据集加载并显示前十行。
import pandas as pd
data = pd.read_csv('./bank-additional/bank-additional-full.csv')
data[:10]将其中一个数据集列命名为 y,代表每个样本的标签:即该客户是否接受此服务?
在这一步中,数据科学家将开始浏览数据、创建新特性等等。使用 Amazon SageMaker Autopilot,您无需采取任何额外步骤。您只需将表格数据(例如,从电子表格或数据库中)上传到带有逗号分隔值的文件中,选择要预测的目标列,Autopilot 就会为您构建一个预测模型。
d.将以下代码复制并粘贴到新的代码单元格中,然后选择运行。
这一步会将 CSV 数据集上传到 Amazon S3 存储桶。您无需创建 Amazon S3 存储桶;当您上传数据时,Amazon SageMaker 会自动在您的账户中创建一个默认存储桶。
import sagemaker
prefix = 'sagemaker/tutorial-autopilot/input'
sess = sagemaker.Session()
uri = sess.upload_data(path="./bank-additional/bank-additional-full.csv", key_prefix=prefix)
print(uri)
完成了! 代码输出显示 S3 存储桶 URI,如下例所示:
s3://sagemaker-us-east-2-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/input/bank-additional-full.csv跟踪印在您自己笔记本中的 S3 URI。下一步中,您需要用到它。

第 4 步:创建 SageMaker Autopilot 实验
现在,您已经在 Amazon S3 中下载并暂存了数据集,您可以开始创建 Amazon SageMaker Autopilot 实验。实验是与同一机器学习项目相关的处理和训练作业的集合。
完成以下步骤以创建新的实验。
注:有关更多信息,请参阅 Amazon SageMaker 文档中的在 SageMaker Studio 中创建 Amazon SageMaker Autopilot 实验。
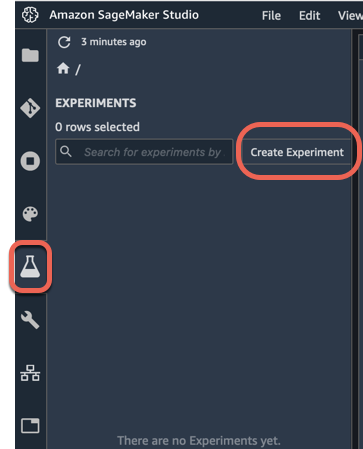
a.在 Amazon SageMaker Studio 左侧的导航窗格中,选择实验(烧瓶样的图标),然后选择创建实验。
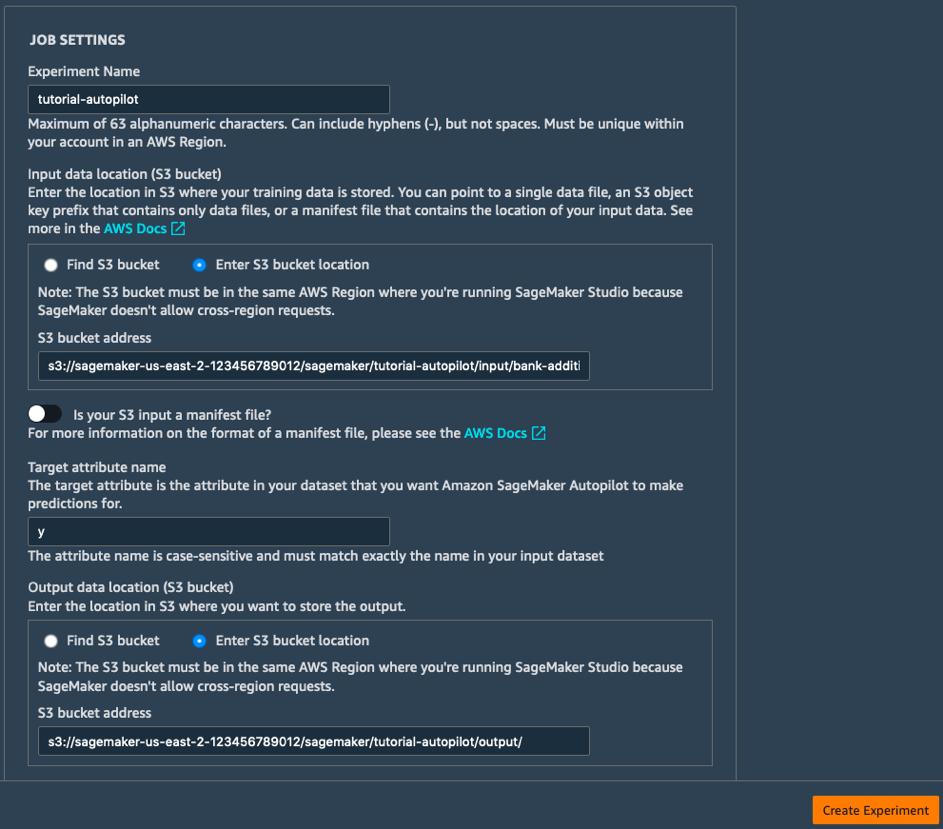
b.按如下方式填写作业设置字段:
- 实验名称: tutorial-autopilot
- 输入数据的 S3 位置:您上面打印的 S3 URI
(例如 s3://sagemaker-us-east-2-123456789012/sagemaker/tutorial-autopilot/input/bank-additional-full.csv) - 目标属性名称:y
- 输出数据的 S3 位置:s3://sagemaker-us-east-2-[ACCOUNT-NUMBER]/sagemaker/tutorial-autopilot/output
(确保用您自己的账号替换 [ACCOUNT-NUMBER])
c.其余设置请保留默认设置,然后选择创建实验。
成功! 这样就创建了 Amazon SageMaker Autopilot 实验! 该过程将生成一个模型和统计数据,您可以在实验运行过程中实时查看这些统计数据。实验完成后,您可以查看它的试运行,按客观指标排序,然后右键单击部署模型以在其他环境中使用。
第 5 步:浏览 SageMaker Autopilot 实验阶段
实验运行过程中,您可以了解和浏览 SageMaker Autopilot 实验的不同阶段。
本节将提供有关 SageMaker Autopilot 实验阶段的更多详细信息:
- 分析数据
- 特征工程
- 模型调优
注:有关更多信息,请参阅 SageMaker Autopilot 笔记本输出。
分析数据
分析数据阶段确定要解决的问题类型(线性回归、二分类、多类别分类)。然后,它会提供十个候选管道。管道使用与问题类型相符的 ML 算法将数据预处理步骤(处理缺失值、设计新特征等)和模型训练步骤结合起来。完成此步骤后,作业将转移到特征工程。
特征工程
在特征工程阶段,实验为每个候选管道创建训练和验证数据集,将所有构件存储在 S3 存储桶中。在特征工程阶段,您可以打开并查看两个自动生成的笔记本:
- 数据浏览笔记本包含有关数据集的信息和统计数据。
- 候选生成笔记本包含十个管道的定义。事实上,这是一个可运行的笔记本:您可以准确地再现 AutoPilot 作业所完成的工作,了解不同模型的构建方式,甚至可以根据需要不断对其进行微调。
通过这两个笔记本,您可以详细了解数据的预处理方式,以及模型的构建和优化方式。透明度是 Amazon SageMaker Autopilot 的一个重要特征。
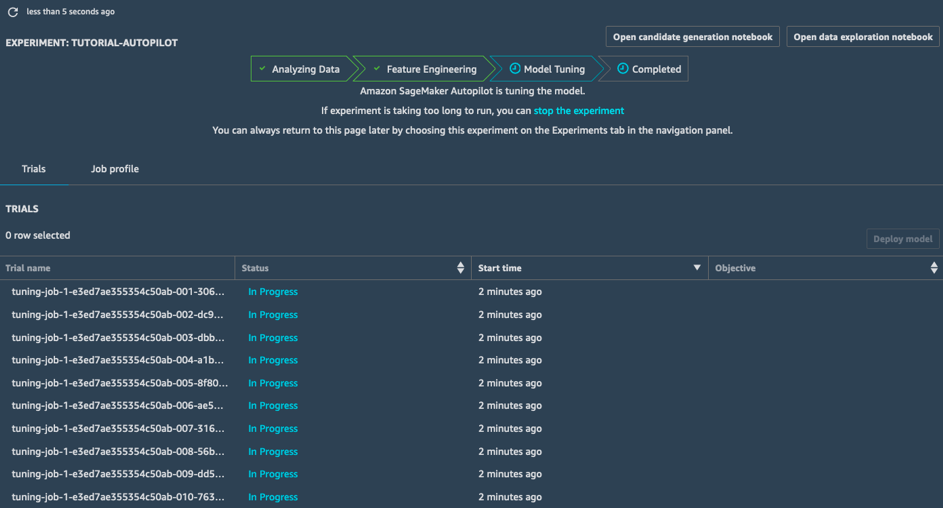
模型调优
在模型调优阶段,对于每个候选管道及其预处理数据集,SageMaker Autopilot 都会启动一个超参数优化作业;相关的训练作业会浏览各种超参数值,并快速汇集到高性能模型中。
本阶段结束后,SageMaker Autopilot 作业也就完成了。您能够查看和浏览 SageMaker Studio 中的所有作业。
第 6 步:部署最佳模型
现在您已完成实验,可以选择最佳的调优模型,并将该模型部署到由 Amazon SageMaker 管理的终端节点。
按照以下步骤选择最佳的调优作业并部署模型。
注:有关更多信息,请参阅选择和部署最佳模型。
a.在实验的试运行列表中,选择目标旁边的胡萝卜标志,按降序对调优作业进行排序。用星号标出最佳调优作业。
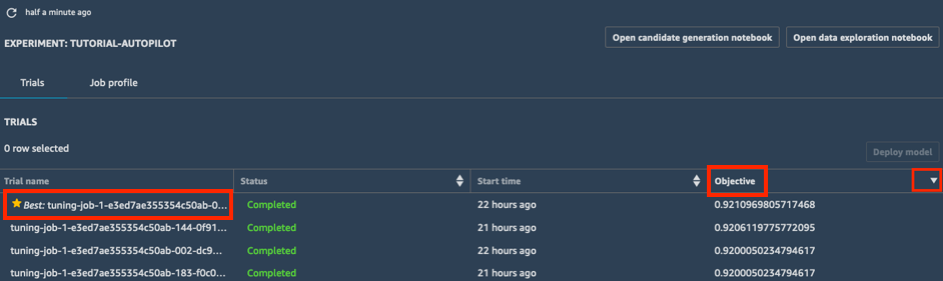
b.选择最佳调优作业(用星号表示),然后选择部署模型。
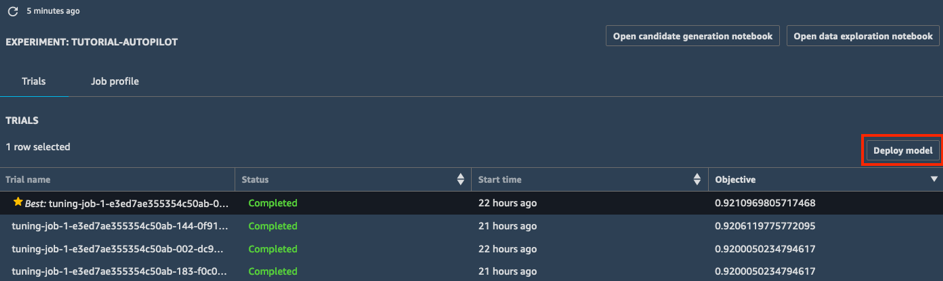
c.在部署模型对话框中,为您的终端节点命名(如 tutorial-autopilot-best-model),并将所有设置保留为默认设置。选择部署模型。
您的模型将部署到由 Amazon SageMaker 管理的 HTTPS 终端节点。
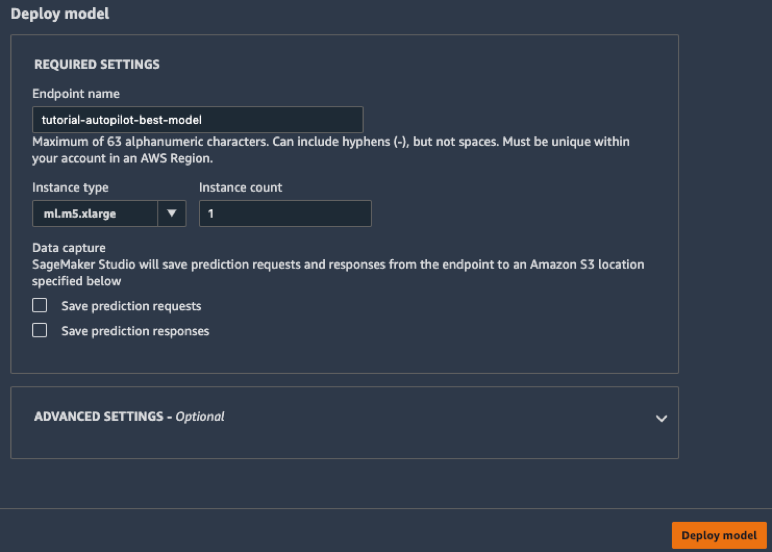
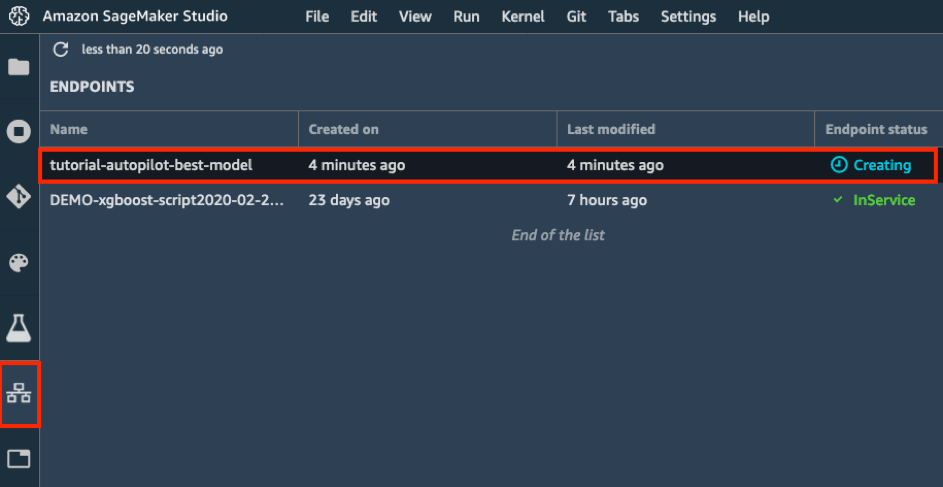
d.在左侧工具栏中,选择终端节点图标。您可以看到您的模型正在创建,这将需要几分钟的时间。当终端节点的状态变为可用时,您就可以发送数据和接收预测了!
第 7 步:用您的模型进行预测
现在已经部署了模型,您可以预测数据集的前 2000 个样本。为此,您将使用 boto3 SDK 中的 invoke_endpoint API。在此过程中,您将计算重要的机器学习指标:准确率、精确率、召回率和 F1 分数。
按照以下步骤使用您的模型进行预测。
注:有关更多信息,请参阅借助 Amazon SageMaker 实验管理机器学习。
在您的 Jupyter 笔记本中,复制并粘贴以下代码,然后选择运行。
import boto3, sys
ep_name = 'tutorial-autopilot-best-model'
sm_rt = boto3.Session().client('runtime.sagemaker')
tn=tp=fn=fp=count=0
with open('bank-additional/bank-additional-full.csv') as f:
lines = f.readlines()
for l in lines[1:2000]: # Skip header
l = l.split(',') # Split CSV line into features
label = l[-1] # Store 'yes'/'no' label
l = l[:-1] # Remove label
l = ','.join(l) # Rebuild CSV line without label
response = sm_rt.invoke_endpoint(EndpointName=ep_name,
ContentType='text/csv',
Accept='text/csv', Body=l)
response = response['Body'].read().decode("utf-8")
#print ("label %s response %s" %(label,response))
if 'yes' in label:
# Sample is positive
if 'yes' in response:
# True positive
tp=tp+1
else:
# False negative
fn=fn+1
else:
# Sample is negative
if 'no' in response:
# True negative
tn=tn+1
else:
# False positive
fp=fp+1
count = count+1
if (count % 100 == 0):
sys.stdout.write(str(count)+' ')
print ("Done")
accuracy = (tp+tn)/(tp+tn+fp+fn)
precision = tp/(tp+fp)
recall = tn/(tn+fn)
f1 = (2*precision*recall)/(precision+recall)
print ("%.4f %.4f %.4f %.4f" % (accuracy, precision, recall, f1))
您应该能看到以下输出:
100 200 300 400 500 600 700 800 900 1000 1100 1200 1300 1400 1500 1600 1700 1800 1900 Done
0.9830 0.6538 0.9873 0.7867
该输出相当于一个进度指示器,显示已预测的样本数量!
第 8 步:清除
在这一步中,您将终止在本实验中使用的资源。
重要说明:终止当前未在使用的资源可降低成本,是最佳做法。不终止资源可能会在您的账户下产生费用。
删除您的终端节点:在您的 Jupyter 笔记本中,复制并粘贴以下代码,然后选择运行。
sess.delete_endpoint(endpoint_name=ep_name)如果您想要清除所有训练构件(模型、预处理数据集等等),请将以下代码复制并粘贴到您的代码单元格中,然后选择运行。
注:确保用您自己的账号替换 ACCOUNT-NUMBER。
%%sh
aws s3 rm --recursive s3://sagemaker-us-east-2-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/建议的后续步骤
了解 Amazon SageMaker Studio
了解有关 Amazon SageMaker Autopilot 的更多信息
如果您想了解更多,请阅读博客文章或观看 Autopilot 系列视频。