概览
您将学到的内容
在本指南中,您将:
- 对数据进行可视化和分析,以理解重要的关系
- 应用转换,以清理数据并生成新的特征
- 自动为可重复的数据准备工作流生成笔记本
先决条件
在开始学习本教程之前,您需要:
- 一个 AWS 账户:如果您还没有账户,请遵循设置 AWS 环境入门指南中的说明获取快速概览。
AWS 使用经验
新手
完成时间
30 分钟
所需费用
请参阅 Amazon SageMaker 定价估算此教程的费用。
需要
您必须登录 AWS 账户。
使用的服务
Amazon SageMaker Data Wrangler
上次更新日期
2022 年 7 月 1 日
实施
第 1 步:设置 Amazon SageMaker Studio 域
使用 Amazon SageMaker,您可以使用控制台可视化地部署模型,也可以使用 SageMaker Studio 或 SageMaker 笔记本以编程方式部署模型。在本教程中,您将使用 SageMaker Studio 笔记本以编程的方式部署模型,该笔记本需要一个 SageMaker Studio 域。
一个 AWS 账户在一个区域只能有一个 SageMaker Studio 域。如果您在美国东部(弗吉尼亚州北部)区域已经有一个 SageMaker Studio 域,请遵照 SageMaker Studio 设置指南将所需的 AWS IAM 策略附加到您的 SageMaker Studio 账户,然后跳过第 1 步,并直接继续第 2 步操作。
如果您没有现有的 SageMaker Studio 域,则继续第 1 步以运行 AWS CloudFormation 模板,从而创建 SageMaker Studio 域并添加本教程剩余部分所需的权限。
选择 AWS CloudFormation 堆栈链接。此链接将打开 AWS CloudFormation 控制台并创建您的 SageMaker Studio 域和名为 studio-user 的用户。它还将添加所需权限到您的 SageMaker Studio 账户。在 CloudFormation 控制台中,确认美国东部(弗吉尼亚州北部) 是右上角显示的区域。 堆栈名称应为 CFN-SM-IM-Lambda-catalog,且不应更改。 此堆栈需要花费 10 分钟左右才能创建所有资源。
此堆栈假设您已经在账户中设置了一个公有 VPC。如果您没有公有 VPC,请参阅具有单个公有子网的 VPC以了解如何创建公有 VPC。

选择 I acknowledge that AWS CloudFormation might create IAM resources(我确认,AWS CloudFormation 可能创建 IAM 资源),然后选择 Create stack(创建堆栈)。

在 CloudFormation 窗格上,选择 Stacks(堆栈)。堆栈约需要 10 分钟才能完成创建。创建堆栈时,堆栈状态从 CREATE_IN_PROGRESS 变为 CREATE_COMPLETE。

第 2 步:创建新的 SageMaker Data Wrangler 流
SageMaker Data Wrangler 接受来自各种源的数据,包括 Amazon S3、Amazon Athena、Amazon Redshift、Snowflake 和 Databricks。在这一步中,您将使用存储在 Amazon S3 的 UCI 德国信用风险数据集来创建新的 SageMaker Data Wrangler 流。此数据集包含有关个人的人口统计及财务信息,以及表示个人信用风险水平的标签。
在管理控制台搜索栏中输入 SageMaker Studio,然后选择 SageMaker Studio。

从 SageMaker 控制台右上角的 Region(区域)下拉列表中选择 US East (N. Virginia)(美国东部(弗吉尼亚州北部))。对于 Launch app(启动应用程序),选择 Studio 以使用 studio-user 配置文件打开 SageMaker Studio。

打开 SageMaker Studio 界面。在导航栏上,选择 File(文件)、New(新建)、Data Wrangler Flow(Data Wrangler 流)。

在 Import(导入)选项卡的 Import data(导入数据)下方,选择 Amazon S3。
在 S3 URI path(S3 URI 路径)字段中,输入 s3://sagemaker-sample-files/datasets/tabular/uci_statlog_german_credit_data/german_credit_data.csv,然后选择 Go(前往)。在 Object name(对象名称)下方,单击 german_credit_data.csv,然后选择 Import(导入)。

第 3 步:分析数据
在这一步中,您要使用 SageMaker Data Wrangler 来评估训练数据集的质量。 您可以使用快速模型功能来大致估算预计的预测质量,以及您的数据集中特征的预测能力。
在 Data Flow(数据流)选项卡的数据流图表中,选择 + 图标以添加分析。
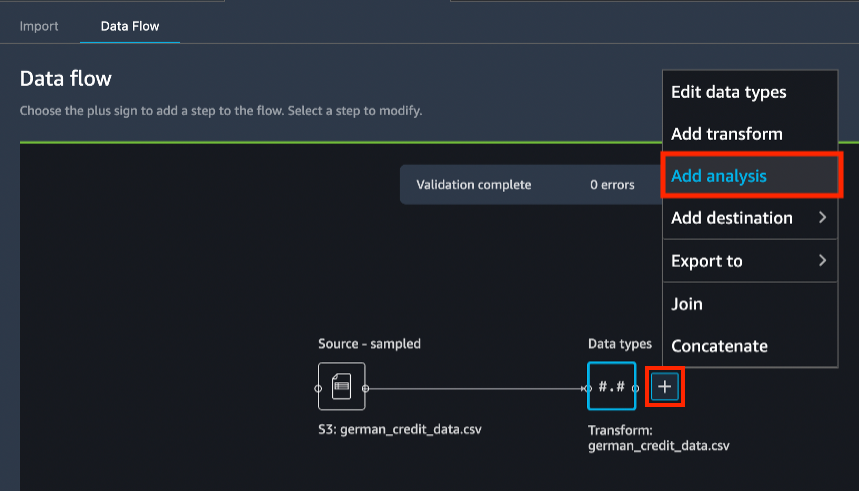
在 Create analysis(创建分析)窗格的下方,为 Analysis type(分析类型)选择 Histogram(直方图)。
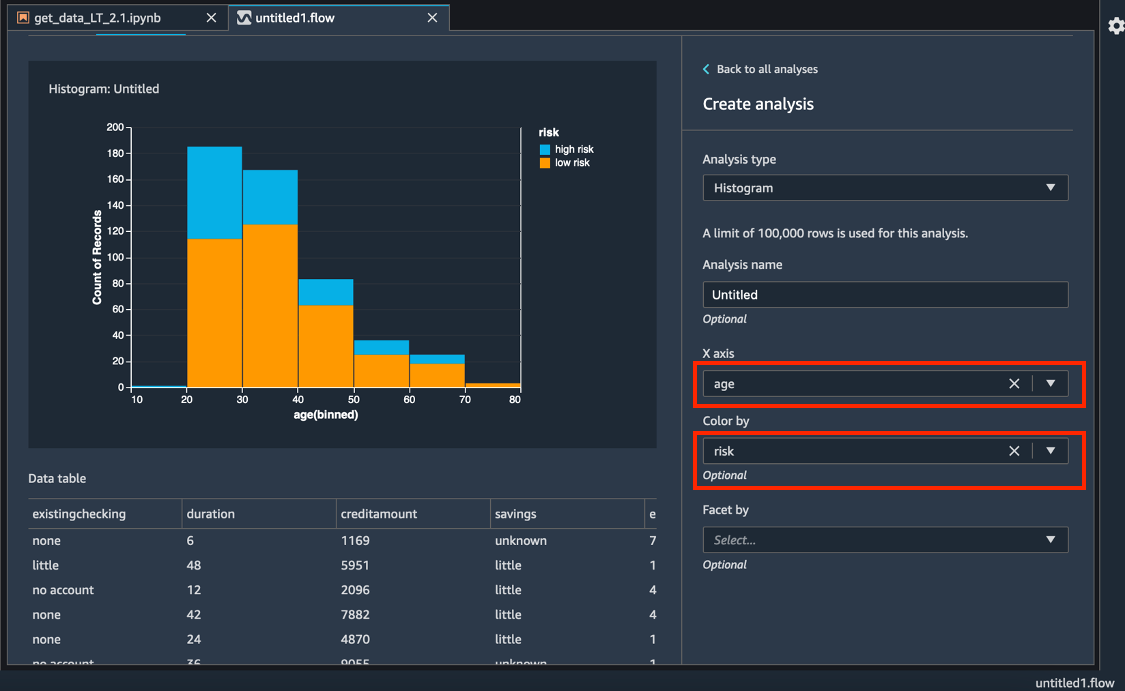
针对 X axis(X 轴),选择 age(年龄)。
对于 Color by(颜色编码依据),选择 risk(风险)。
选择 Preview(预览),以生成 credit risk(信用风险)字段的直方图,并按 age(年龄)括号中的信息进行颜色编码。
选择 Save(保存)以便将此分析保存到流中。
要了解数据集多么适合被用于训练可预测 risk(风险)目标变量的模型,请允许快速模型分析。在 Analysis(分析)选项卡中,选择 Create new analysis(创建新的分析)。
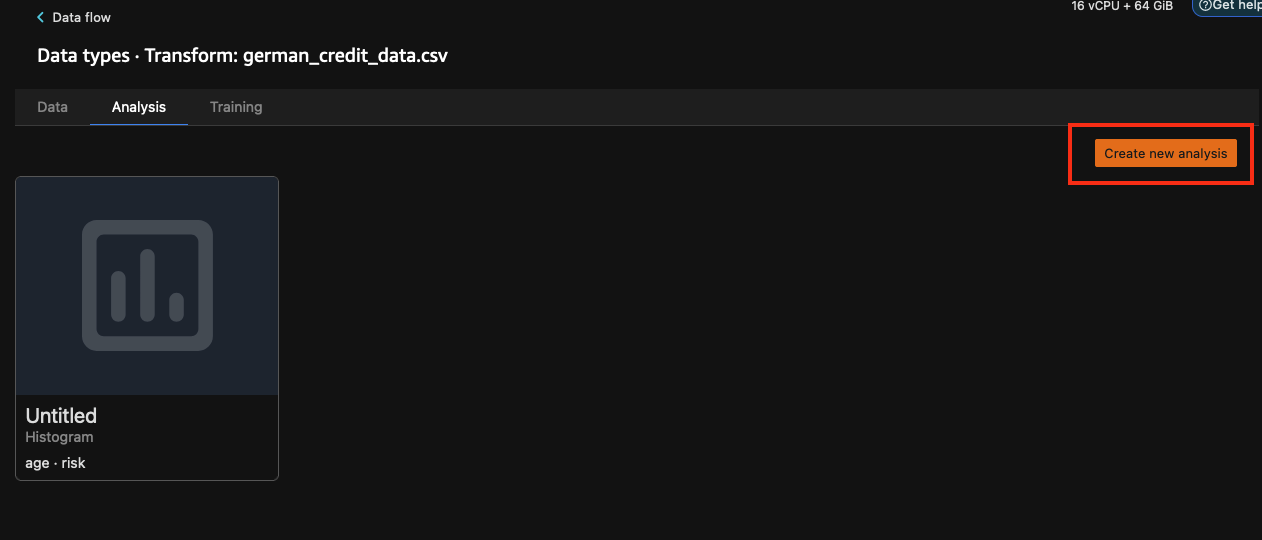
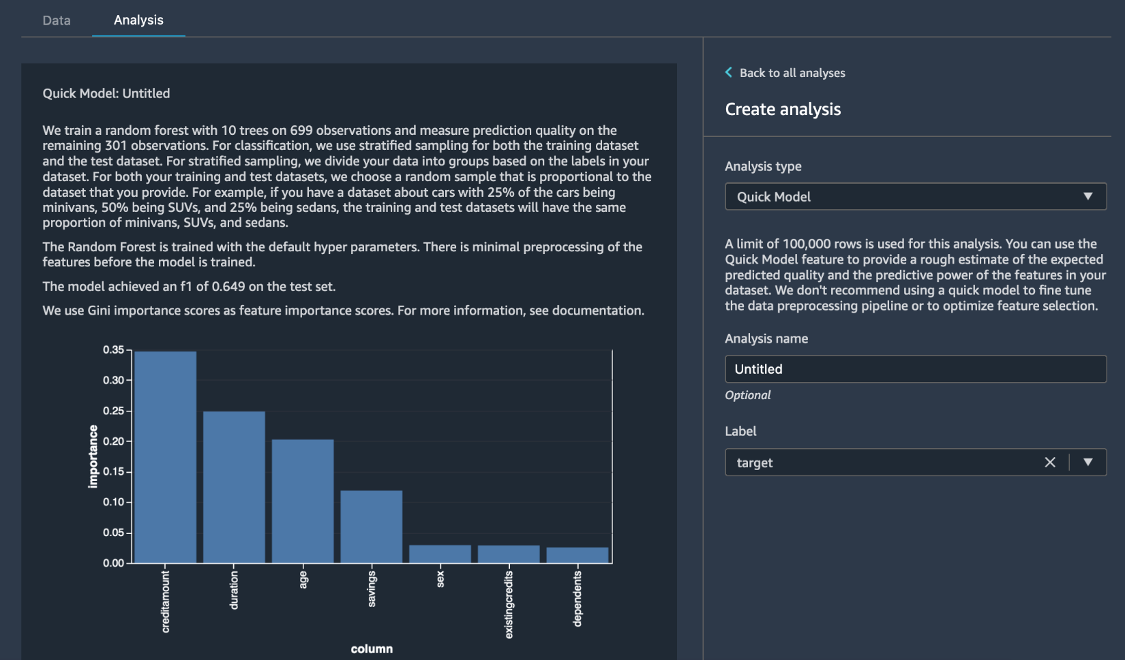
在 Create analysis(创建分析)窗格的下方,为 Analysis type(分析类型)选择 Quick Model(快速模型)。对于 Label(标签),选择 risk(风险),然后选择 Preview(预览)。 Quick Model(快速模型)窗格将显示所用模型以及一些基本统计数据的简要概览,包括 F1 分数和特征重要性等,以帮助您评估数据集的质量。选择 Save(保存)。
第 4 步:添加转换到数据流
SageMaker Data Wrangler 会通过提供可视化界面来简化数据处理,您可以使用该界面添加各种预构建的转换。您还可以使用 SageMaker Data Wrangler 编写您的自定义转换。 在这一步中,您要使用可视化编辑器对复杂的字符串数据进行平铺、类别编码、重命名列,以及删除不必要的列。 然后,您要将 status_sex 列分割成两个新列:marital_status 和 sex。
要导航到数据流图表,请选择 Data flow(数据流)。

在数据流图表中,选择 + 图标以添加转换。

在 ALL STEPS(所有步骤)窗格下方,选择 Add step(添加步骤)。

在 ADD TRANSFORM(添加转换)列表中,选择 Search and edit(搜索并编辑),它是用于操作字符串数据的转换。

在 SEARCH AND EDIT(搜索并编辑)窗格下方,为 Transform(转换)选择 Split string by delimiter(以分隔符分割字符串)。 对于 Input columns(输入列),选择 status_sex。 在 Delimiter(分隔符)框中,输入 : 符号。 在 Output column(输出列)中,输入 vec。选择 Preview(预览),然后选择 Add(添加)。
此转换会分割 status_sex 列,在数据框架的末尾创建名为 vec 的新列。status_sex 列包含以冒号分隔的字符串,新的 vec 列则包含以逗号分隔的向量。

要分割 vec 列并创建两个新列,sex_split_0 和 sex_split_1:
在 ALL STEPS(所有步骤)下方,选择 + Add step(+ 添加步骤)。
在 ADD TRANSFORM(添加转换)列表中,选择 Manage vectors(管理向量)。
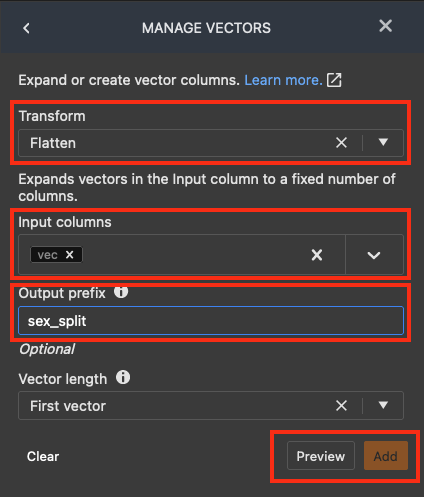
在 MANAGE VECTORS(管理向量)窗格下方,为 Transform(转换)选择 Flatten(平铺)。 对于 Input columns(输入列),选择 vec。对于 output_prefix,输入 sex_split。
选择 Preview(预览),然后选择 Add(添加)。
要重命名由分割转换创建的列:
在 ALL STEPS(所有步骤)窗格下方,选择 + Add step(+ 添加步骤)。
在 ADD TRANSFORM(添加转换)列表中,选择 Manage columns(管理列)。
在 MANAGE COLUMNS(管理列)窗格下方,为 Transform(转换)选择 Rename column(重命名列)。对于 Input column(输入列),选择 sex_split_0。 在 New name(新名称)框中,输入 sex。
选择 Preview(预览),然后选择 Add(添加)。
重复此过程,将 sex_split_1 重命名为 marital_status。

第 5 步:添加类别编码
在这一步中,您要创建建模目标,并对类别变量进行编码。类别编码会将字符串数据类型类别转换为数字标签。这是一项常见的预处理任务,因为数字标签可被用于各种模型类型。
在数据集中,信用风险分类以字符串 high risk(高风险)和 low risk(低风险)表示。在这一步中,您要将此分类转换为二进制表示,0 或 1。
在 ALL STEPS(所有步骤)窗格下方,选择 + Add Step(+ 添加步骤)。在 ADD TRANSFORM(添加转换)列表中,选择 Encode categorical(类别编码)。SageMaker Data Wrangler 提供三种转换类型:有序编码、独热编码和相似度编码。在 ENCODE CATEGORICAL(类别编码)窗格下方,为 Transform(转换)保留默认的 Ordinal encode(有序编码)。 对于 Input columns(输入列),选择 risk。 在 Output column(输出列)中,输入 target。 本教程将忽略 Invalid handling strategy(无效处理策略)框。 选择 Preview(预览),然后选择 Add(添加)。

# Table is available as variable ‘df’
savings_map = {"unknown":0, "little":1, "moderate":2, "high":3, "very high":4}
df["savings"] = df["savings"].map(savings_map).fillna(df["savings"])

使用 Encode categorical(类别编码)转换对其余列(housing、job、sex 和 marital_status)进行编码,具体操作如下:在 ALL STEPS(所有步骤)下方,选择 + Add Step(+ 添加步骤)。 在 ADD TRANSFORM(添加转换)列表中,选择 Encode categorical(类别编码)。在 ENCODE CATEGORICAL(类别编码)窗格下方,为 Transform(转换)保留默认的 Ordinal encode(有序编码)。 对于 Input columns(输入列),选择 housing、job、sex 和 marital_status。Output column(输出列)留空,因此编码值会取代类别值。选择 Preview(预览),然后选择 Add(添加)。

要扩展数字列 creditamount,对信用金额应用缩放器以便对此列中的数据分布进行标准化:在 ALL STEPS(所有步骤)窗格下方,选择 + Add Step(+ 添加步骤)。 在 ADD TRANSFORM(添加转换)列表中,选择 Process numeric(处理数字)。对于 Scaler(缩放器),选择默认选项 Standard scaler(标准缩放器)。对于 Input columns(输入列),选择 creditamount。选择 Preview(预览),然后选择 Add(添加)。


要删除您已转换的原始列:在 ALL STEPS(所有步骤)窗格下方,选择 + Add Step(+ 添加步骤)。在 ADD TRANSFORM(添加转换)列表中,选择 Manage columns(管理列)。在 MANAGE COLUMNS(管理列)窗格下方,为 Transform(转换)选择 Drop Column(删除列)。 在 Columns to drop(要删除的列)中,选择 status_sex、existingchecking、employmentsince、risk 和 vec。选择 Preview(预览),然后选择 Add(添加)。

第 6 步:运行数据偏差检查
在这一步中,使用 Amazon SageMaker Clarify 检查您的数据偏差,您可以通过它更清楚地了解您的训练数据和模型,以便您可以识别和限制偏差,并解释预测。
选择左上角的 Data flow(数据流)以返回至数据流图表。选择 + 图标以 Add analysis(添加分析)。在 Create analysis(创建分析)窗格中,为 Analysis type(分析类型)选择 Bias Report(偏差报告)。对于 Analysis name(分析名称),输入任何名称。为 Select the column your model predicts (target)(选择您的模型预测的(目标)列)选择 target(目标)。保持勾选 Value(值)复选框。在 Predicted value(s)(预测值)框中,输入 1。对于 Select the column to analyze for bias(选择要进行偏差分析的列),选择 sex。对于 Choose bias metrics(选择偏差指标),保留默认选择。选择 Check for bias(检查偏差)。
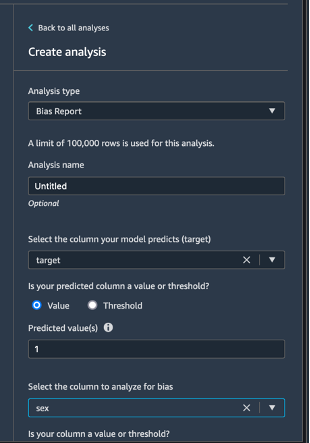
几秒后,SageMaker Clarify 会生成一份报告,显示有关一系列偏差相关指标的目标和测试列分数,其中包括类不平衡(CI)和标签中正比例的差异(DPL)。在此例中,数据在 sex 方面有些许偏差(-0.38),在 labels 方面的偏差较小(0.075)。根据此报告,您可能要考虑偏差补偿方法,例如,使用 SageMaker Data Wrangler 的内置 SMOTE 转换。在本教程中,我们将跳过补偿步骤。选择 Save(保存)以便将偏差报告保存到数据流。

第 7 步:导出您的数据流
将您的数据流导出到 Jupyter notebook,像 SageMaker Processing 作业那样执行步骤。这些步骤会根据您定义的数据流处理数据,并将输出存储到 Amazon S3 或 Amazon SageMaker Feature Store。
在数据流图表中,选择 + 图标以导出到 Amazon S3(通过 Jupyter Notebook)。这将会在 SageMaker Studio 中创建笔记本,您可以在其中运行生成的 SageMaker Processing 作业以创建转换数据集。 运行此笔记本,以便将结果存储到默认的 S3 桶。



第 8 步:清理资源
最佳实践是删除您不再使用的资源,以免产生意外费用。
要删除 S3 桶,请执行以下操作:
- 打开 Amazon S3 控制台。在导航栏上,选择 Buckets(桶)、sagemaker-<your-Region>-<your-account-id>,然后选择 data_wrangler_flows 旁的复选框。然后选择 Delete(删除)。
- 在 Delete objects(删除对象)对话框中,确认您是否已选中要删除的正确对象,并在 Permanently delete objects(永久删除对象)确认框中输入 permanently delete。
- 当此操作完成且桶为空时,您可以通过再次遵循相同程序来删除 sagemaker-<your-Region>-<your-account-id> 桶。

本教程中用于运行笔记本图像的数据科学内核将不断累积费用,直到您停止内核或执行以下步骤删除应用程序。 有关更多信息,请参阅 Amazon SageMaker 开发人员指南中的关闭资源。
要删除 SageMaker Studio 应用程序,请执行以下操作:在 SageMaker Studio 控制台中,选择 studio-user,然后通过选择 Delete app(删除应用程序)来删除 Apps(应用程序)下列出的所有应用程序。等待片刻直到状态更改为 Deleted(已删除)。

如果您在第 1 步中使用了一个现有的 SageMaker Studio 域,则跳过第 8 步的其余部分,直接进入结论部分。
如果您在第 1 步运行 CloudFormation 模板来创建新的 SageMaker Studio 域,请继续执行以下步骤以删除由 CloudFormation 模板创建的域、用户和资源。
要打开 CloudFormation 控制台,请在 AWS 管理控制台搜索栏中输入 CloudFormation,然后从搜索结果中选择 CloudFormation。

在 CloudFormation 窗格上,选择 Stacks(堆栈)。从 Status(状态)下拉列表中,选择 Active(活动)。在 Stack name(堆栈名称)下方,选择 CFN-SM-IM-Lambda-catalog 以打开堆栈详细信息页面。

在 CFN-SM-IM-Lambda-catalog 堆栈详细信息页面上,选择 Delete(删除)以删除堆栈以及在第 1 步中创建的资源。

结论
您已成功使用 Amazon SageMaker Data Wrangler 为机器学习模型准备训练数据。SageMaker Data Wrangler 提供了 300 多种预配置的数据转换选择,例如转换列类型、独热编码、使用均值或中值插补缺失数据、重新缩放列以及日期/时间嵌入,因此您可以将数据转换为可有效用于模型的格式,而无需编写任何代码。