实时数据分析服务和 Apache Flink 助力 SQL 开发人员




- Kinesis Data Streams
- Kinesis Data Analytics
- S3 存储桶
- Glue Data Catalog


实时数据分析有助于企业识别新兴趋势或客户行为的变化,同时还能实时监控重要事件,从而帮助企业领先于竞争对手。常见的实时数据分析使用场景包括:
- 分析点击流,确定客户行为
- 分析物联网设备的实时事件
- 将分析结果数据同步到实时控制面板
- 触发实时通知和警报
与传统的分析方法相比,为了实现实时分析,我们需要一套特别的工具来收集和分析流数据。所需的基础设施包括 Amazon Kinesis Data Streams (KDS) 或 Apache Kafka 等消息传递系统,用于捕获实时数据;以及 Amazon Kinesis Data Analytics (KDA) 或 Apache Spark 等实时处理引擎,用于快速处理和分析传入的信息。本次试验中,我们将数据注入到 Kinesis Data Streams,并使用 Amazon Kinesis Data Analytics for Apache Flink 进行分析。
Apache Flink 是一个开源流处理引擎,用于处理流数据和批量数据,以实现分析、ETL 流程和数据管道。其功能核心是提供分布式处理和容错能力的流运行时。熟悉 SQL 的开发人员可使用 Apache Flink 轻松处理和分析流数据。Flink 支持事件处理、时间窗口和聚合的 SQL 语法。这种结合将其打造成了一个高效的流式查询引擎。
Amazon Kinesis Data Analytics (KDA) 是一种全托管服务,支持使用 SQL 或基于 Java、Scala 和 Python 等语言的应用来分析实时流数据。Amazon KDA 以 Apache Flink 为基础,简化了 Apache Flink 应用程序的构建和维护,以及降低了应用与其他亚马逊云科技服务集成的复杂性。
在 KDA 中,可以通过 KDA Studio 记事本执行 SQL 查询。KDA Studio 笔记本基于 Apache Zeppelin,支持以交互方式实时查询数据流和开发基于 SQL、Python 和 Scala 的流处理应用程序。您可以在亚马逊云科技管理控制台快速启动无服务器笔记本,查询数据流和查看结果。KDA Studio 笔记本提供了用户友好的交互式开发体验,同时利用了 Apache Flink 提供的强大功能。
学习内容
- 如何使用 KDA Studio 笔记本实现流数据 SQL 查询
- 如何将 KDA Studio 笔记本部署为持久性 KDA 应用程序
构建内容
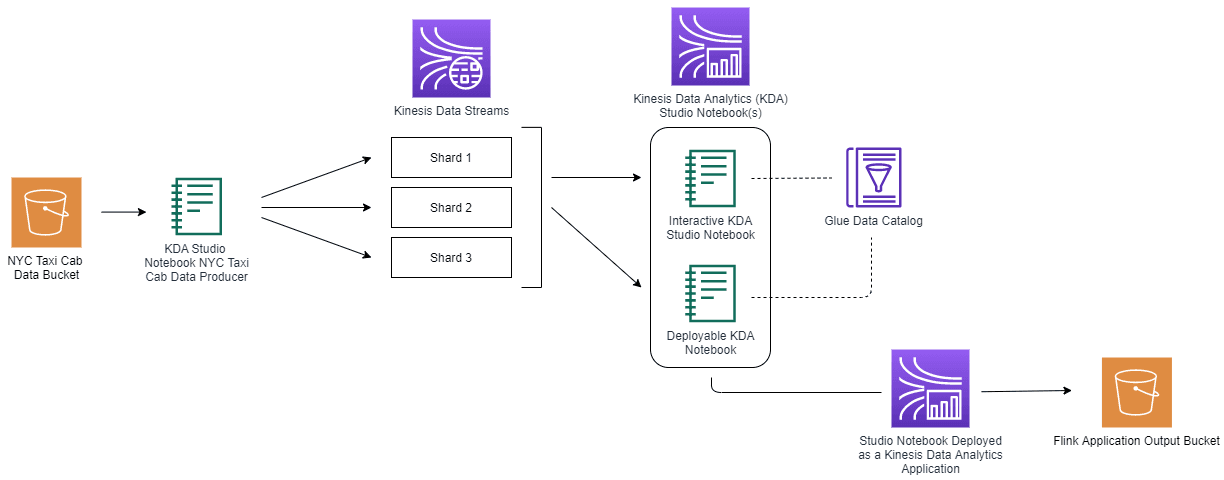
此解决方案部署包括以下步骤:
- 准备数据。此实验中,我们的示例数据来自 NYC Taxi Cab Trips 数据集,其中包括上下车日期/时间/地点、行程距离等字段。这些数据将以流数据形式运行。我们将用另一个文件中提供的 Taxi Zone Geohash 数据来丰富这个数据集。
- 通过 KDA Studio 笔记本将数据从 S3 注入到 KDS
- 在 KDA Studio 笔记本中运行 SQL 来分析数据
- 将处理后的数据写入 S3 存储桶
- 构建和部署 KDA 应用程序
实操步骤
设置环境
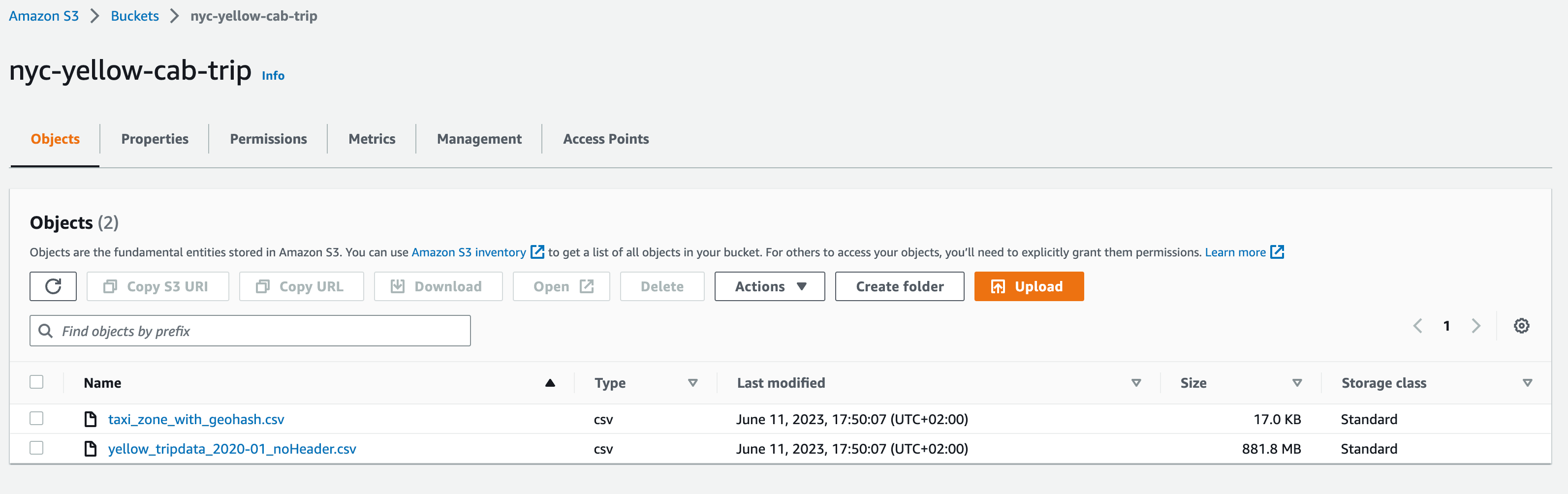
创建 Amazon S3 存储桶并上传示例数据
- 前往 S3 控制台。
- 点击 Create bucket(创建存储桶)。
- 输入存储桶名称。
- 其他设置保留默认值,然后点击 Create bucket(创建存储桶)。
- 上传包含流数据的 NYC Taxi Cab Trips 文件和为了丰富流数据的 Taxi Zone Geohash 文件。
S3 存储桶中的文件应如下所示。
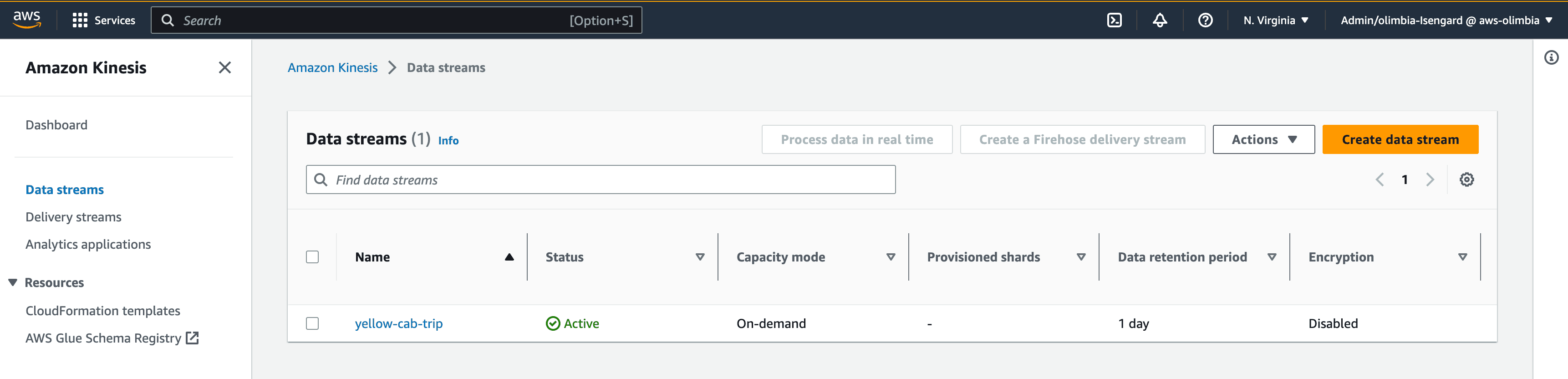
创建 Kinesis 数据流
- 前往 Kinesis 控制台。
- 在 Data streams(数据流)下,点击 Create data stream(创建数据流)。
- 将该 Kinesis 数据流命名为 yellow-cab-trip。
- 其他设置保留默认值,然后点击 Create data stream(创建数据流)。
创建 Kinesis Data Analytics Studio 笔记本
- 前往 Kinesis Data Analytics 控制台。
- 点击 Studio。
- 点击 Create Studio Notebook(创建 Studio 笔记本)。
- 在创建方法部分,选择 Create with custom settings(使用自定义设置创建)。
- 输入 Studio 笔记本的名称。
- 选择 Apache Flink 1.13, Apache Zeppelin 0.9。
- 点击 Next(下一步)。
- 在 IAM 角色部分下,选择 Create / Update IAM role ... with required policies(创建/更新具有所需策略的 IAM 角色...)。记录 IAM 角色的名称。
- 在 Amazon Glue 数据库部分,点击 Create(创建)。这将在您的 Web 浏览器中打开一个新标签页/窗口。
- 在打开的新窗口中,点击 Add database(添加数据库)。
- 输入数据库名称。
- 点击 Create(创建)。
- 关闭该窗口,然后返回配置 Kinesis Data Analytics Studio 部署的窗口
- 在 Amazon Glue 数据库部分,点击刷新按钮,然后从下拉列表中选择刚刚创建的数据库。
- 其余设置保留默认值,然后点击页面底部的 Next(下一步)。
- 在 Deploy as application configuration - optional(部署为应用程序配置 - 可选)部分中,点击 Browse(浏览),然后选择前面创建的 S3 存储桶。
- 其余设置保留默认值,然后点击页面底部的 Next(下一步)。
- 点击页面底部的 Create Studio Notebook(创建 Studio 笔记本)。
添加 IAM 权限
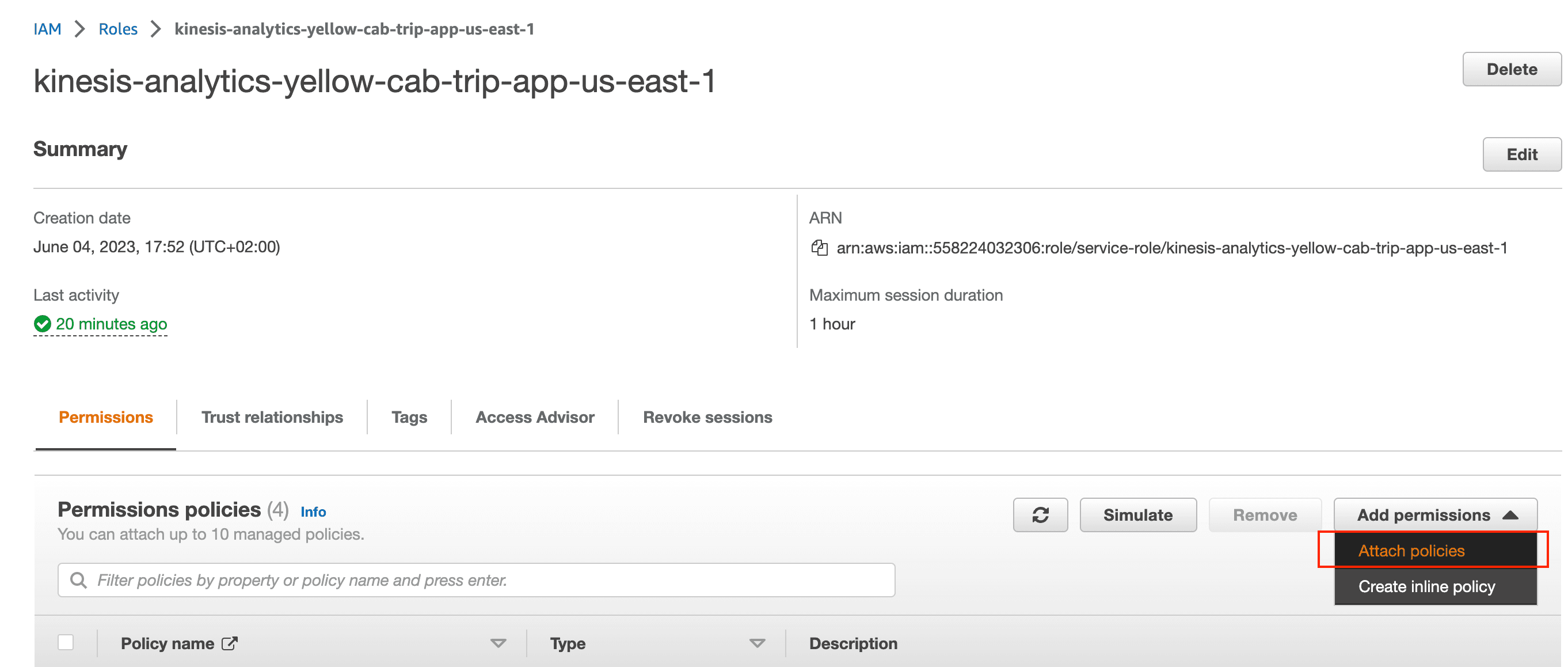
- 前往 IAM 控制台中的角色页面。
- 搜索创建 KDA Studio 的步骤 8 中所创建角色的名称。
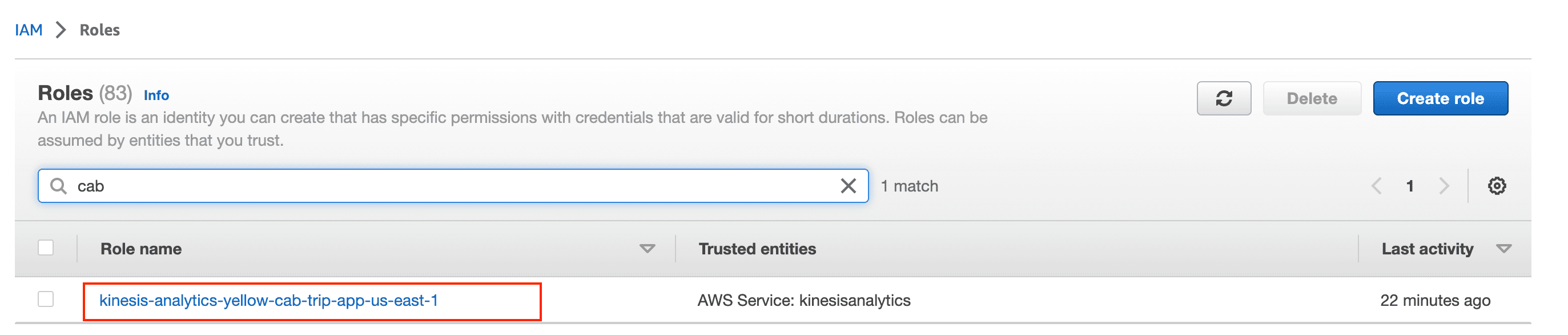
- 点击 Add permission(添加权限),然后点击 Attach policies(附加策略)。
- 搜索并添加 AmazonS3FullAccess、AmazonKinesisFullAccess 和 AWSGlueServiceRole 权限策略。
- 现在我们已经设置了环境,下面开始使用 SQL 运行一些分析查询。
流分析
将存储在 S3 存储桶中的数据注入到 Kinesis 数据流
Zeppelin 笔记本中的笔记是用户创建的单个文档,这些文档可以包含代码、文本、图像和可视化视图的组合。这些笔记可用于记录数据处理步骤、传达调查发现和共享数据洞察结果。您可以创建新笔记、打开现有笔记、导入和导出笔记,以及将笔记整理到文件夹中。
下面,我们创建一个将数据从 S3 注入到 Kinesis Data Streams 的新笔记。
在 KDA Studio 笔记本 (Zeppelin) 中创建笔记
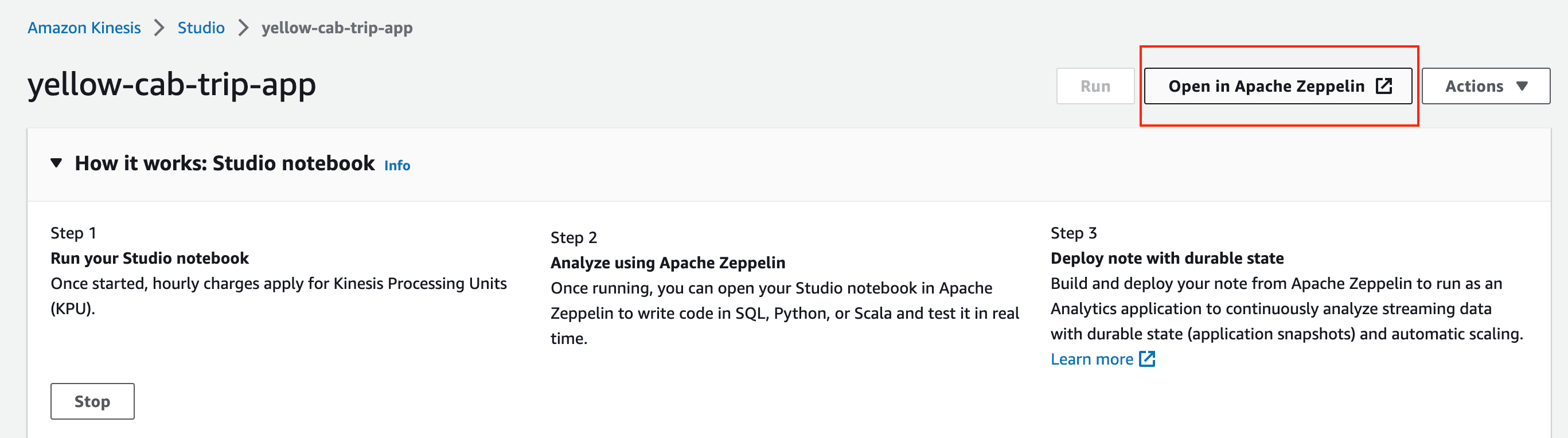
- 前往 Kinesis Data Analytics 控制台。
- 点击 Studio。
- 点击您的 KDA Studio 实例。
- 点击 Run(运行)。
- 点击 Open in Apache Zeppelin(在 Apache Zeppelin 中打开)。
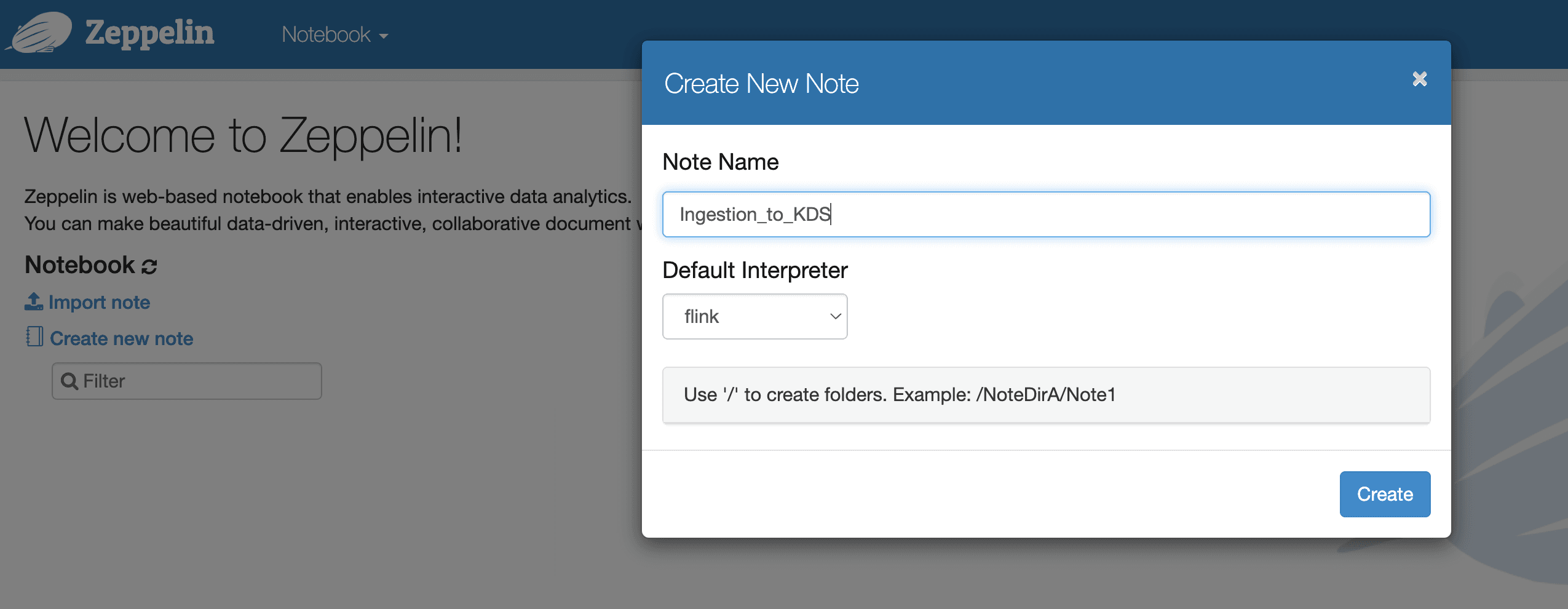
6. 点击 Create new note(创建新笔记本),然后选择 Flink 作为 Default Interpreter(默认解释器)。
SQL
可以在 Flink 中运行第一个 SQL 查询了。
与传统数据库不同,Flink 不在本地管理静态数据,而是不断从外部表查询数据。这些表的元数据将存储在我们前面定义的 Amazon Glue Data Catalog 中。
Flink 查询在表上运行。理论上,需要有两种类型的表:源表和接收表,因此我们需要创建一个表来引用存储在 S3 存储桶中的数据,创建另一个表来引用存储 Kinesis Data Streams 中的数据。
请将路径中的 <BUCKET_NAME> 替换为您的 S3 存储桶名称。
下面的代码用于定义一个引用存储在 S3 中的出行数据的源表。
%flink.ssql
DROP TEMPORARY TABLE IF EXISTS s3_yellow_trips;
CREATE TEMPORARY TABLE s3_yellow_trips (
`VendorID` INT,
`tpep_pickup_datetime` TIMESTAMP(3),
`tpep_dropoff_datetime` TIMESTAMP(3),
`passenger_count` INT,
`trip_distance` FLOAT,
`RatecodeID` INT,
`store_and_fwd_flag` STRING,
`PULocationID` INT,
`DOLocationID` INT,
`payment_type` INT,
`fare_amount` FLOAT,
`extra` FLOAT,
`mta_tax` FLOAT,
`tip_amount` FLOAT,
`tolls_amount` FLOAT,
`improvement_surcharge` FLOAT,
`total_amount` FLOAT,
`congestion_surcharge` FLOAT
)
WITH (
'connector' = 'filesystem',
'path' = 's3://<BUCKET_NAME>/reference_data/yellow_tripdata_2020-01_noHeader.csv',
'format' = 'csv'
);下面的代码定义一个引用存储在 Kinesis Data Streams 中的数据的接收表。
%flink.ssql
DROP TEMPORARY TABLE IF EXISTS kinesis_yellow_trips;
CREATE TEMPORARY TABLE kinesis_yellow_trips (
`VendorID` INT,
`tpep_pickup_datetime` TIMESTAMP(3),
`tpep_dropoff_datetime` TIMESTAMP(3),
`passenger_count` INT,
`trip_distance` FLOAT,
`RatecodeID` INT,
`store_and_fwd_flag` STRING,
`PULocationID` INT,
`DOLocationID` INT,
`payment_type` INT,
`fare_amount` FLOAT,
`extra` FLOAT,
`mta_tax` FLOAT,
`tip_amount` FLOAT,
`tolls_amount` FLOAT,
`improvement_surcharge` FLOAT,
`total_amount` FLOAT,
`congestion_surcharge` FLOAT
)
WITH (
'connector' = 'kinesis',
'stream' = 'yellow-cab-trip',
'aws.region' = 'us-east-1',
'format' = 'json'
);使用 INSERT INTO 语句将数据注入到 KDS 中,并将 S3 源表中的所有数据插入到 Kinesis 接收表中。
%flink.ssql(type=update, parallelism=1)
INSERT INTO kinesis_yellow_trips SELECT * FROM s3_yellow_trips这样,就可以将数据发送到 Kinesis 数据流。不要关闭该浏览器窗口,确保笔记本持续运行。这将确保在进行本实验的下一部分时,可继续向您的 Kinesis 数据流发送数据。
注意:Ingestion_to_KDS 向 Kinesis 数据流发送数据的持续时间约 30 分钟。您可能需要定期重新运行笔记本,以向 Kinesis 数据流注入采样数据。如果您在使用后续笔记本时没有看到任何返回结果,请检查您的笔记是否仍在运行,是否需要重启。
有关将数据摄取到 KDS 的 Zeppelin 笔记的详细信息,请访问此链接。
在 KDA Studio 笔记本中运行 SQL 来分析数据
将数据注入到 KDS 中后,创建一个新的 Zeppelin 笔记,我们就可以进行分析查询。
查询 1:统计纽约市每个行政区的出行人次
要统计纽约市每个行政区的出行人次,我们需要上车地点信息。
trips 表中的数据包含上车地点 ID (PULocationID),但不包含所在的行政区信息。而在 S3 上名为 taxi_zone_with_geohash.csv 的文件中,包含每个 LocationID 对应的行政区信息。
首先,我们需要创建一个表来引用 taxi_zone_with_geohash.csv 文件中的数据。
%flink.ssql
DROP TABLE IF EXISTS locations;
CREATE TABLE locations (
`LocationID` INT,
`borough` STRING,
`zone` STRING,
`service_zone` STRING,
`latitude` FLOAT,
`longitude` FLOAT,
`geohash` STRING
) WITH (
'connector'='filesystem',
'path' = 's3://<BUCKET_NAME>/taxi_zone_with_geohash.csv',
'format' = 'csv',
'csv.ignore-parse-errors' = 'true'
)定义了引用表后,我们可以在将原始的源流数据表 trip 与引用表 locations 上同时执行查询。
%flink.ssql(type=update)
SELECT
locations.borough as borough,
COUNT(*) as total_trip_pickups
FROM trips
JOIN locations
ON trips.PULocationID = locations.LocationID
GROUP BY locations.borough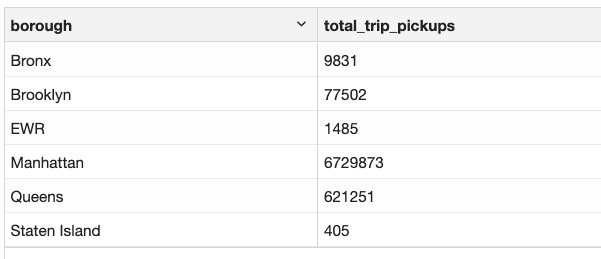
查询 2:统计每小时曼哈顿的出行人次
此查询的目的是确定曼哈顿地区出租车需求量在哪个时间窗口最大。为此,我们将引入流式窗口。
Apache Flink 中的窗口是一种将流分为一系列有限子流的方法,每个子流包含特定时间范围内的所有事件。可以将子流作为独立的单元来执行计算和分析。
Flink 支持滚动窗口。滚动窗口是一种固定大小的非重叠窗口,将流划分为一系列长度相等的非重叠窗口。每个窗口的开始时间由固定的窗口大小决定。在本例中,我们将定义间隔一小时的滚动窗口。
%flink.ssql(type=update)
SELECT COUNT(*) AS total_trip_pickups
FROM trips
WHERE EXISTS (
SELECT *
FROM locations
WHERE locations.LocationID = trips.PULocationID
AND locations.Borough = 'Manhattan'
)
GROUP BY TUMBLE(trips.tpep_dropoff_datetime, INTERVAL '60' MINUTE)
有关分析查询的 Zeppelin 笔记的详细信息,请访问此链接。
将查询结果写入 S3
运行分析查询后,我们可以同步输出结果以更新实时控制面板或将结果数据写入其他流。在本例中,我们将查询结果发送到 S3。
我们可以像将数据注入到 Kinesis Data Streams 一样,通过 INSERT INTO 语句写入 SQL 查询的结果。首先,我们需要定义一个接收表,将数据写入其中,然后执行相应的查询。
%flink.ssql(type=update)
CREATE TABLE s3_query1 (
`borough` STRING,
`total_trip_pickups` INT
) WITH (
'connector'='filesystem',
'path' = 's3://<BUCKET_NAME>/query1',
'format' = 'json'
)下面的示例代码用于将查询 1 的结果发送到 S3。
%flink.ssql(type=update, parallelism=1)
INSERT INTO s3_query1
SELECT
locations.borough as borough,
COUNT(*) as total_trip_pickups
FROM trips
JOIN locations
ON trips.PULocationID = locations.LocationID
GROUP BY locations.borough构建 KDA Studio 笔记本并将其部署为持久性应用程序
KDA Studio 笔记本可以实时运行和获取结果,因此可以用于以交互方式开发和测试查询。我们需为生产 Flink 应用程序部署 Studio 笔记本。这就会创建一个持续运行的应用程序,从数据源读取数据、执行分析、将数据写入指定目标。此应用程序将根据源数据流的吞吐量自动扩展。要构建和部署 KDA Studio 笔记本,需要执行以下步骤:
- 在右上角 Actions(操作)下拉列表中,选择第一个选项 Build <Filename>(构建 <文件名称>)。 <Filename>
- 等待构建完成。此过程可能需要几分钟。
- 在 Actions(操作)下拉列表中,选择 Deploy <Filename>(部署 <文件名称>)。 <Filename>
- 所有其他设置保留默认值,然后点击 Create Streaming Application(创建流应用程序)。
- 等待部署完成。此过程可能需要几分钟。
- 部署完成后,前往 Kinesis Data Analytics 控制台。
- 创建的的应用程序将显示在 Streaming applications(流应用程序)下。
- 选中该程序,然后点击 Run(运行)。
- 现在,该 KDA Studio 笔记本已部署为 KDA 应用程序。
有关用于部署的 Zeppelin 笔记的详细信息,请访问此链接。
清理资源
试验完成后,请及时删除本实操教程中创建的资源。
删除 Kinesis 数据流
- 前往 Kinesis Data Streams 控制台。
- 选择要删除的数据流。
- 点击 Actions(操作),然后选择 Delete(删除)。
删除 S3 存储桶
- 前往 S3 控制台。
- 选择要删除的 S3 存储桶,然后点击 Delete(删除)。
删除 KDA Studio 笔记本和 KDA 应用程序
- 前往 Kinesis Data Analytics 控制台。
- 选择要删除的 流应用程序。
- 点击 Actions(操作),然后选择 Delete(删除)。
- 点击 Studio。
- 选择要删除的 Studio 笔记本。
- 点击 Actions(操作),然后选择 Delete(删除)。
总结
您已经学习了如何使用 Kinesis Data Analytics Studio 笔记本通过 Flink SQL 分析流数据,以及如何创建和部署持久性流应用程序。您还可以使用 Java、Python 和 Scala 等编程语言来编写数据分析应用。详细信息,请访问 Sreaming Analytics Workshop。
祝您快乐!

