Amazon SageMaker Data Wrangler
The fastest and easiest way to prepare data for machine learning - now in SageMaker Canvas
Why SageMaker Data Wrangler?
Amazon SageMaker Data Wrangler reduces data prep time for tabular, image, and text data from weeks to minutes. With SageMaker Data Wrangler you can simplify data preparation and feature engineering through a visual and natural language interface. Quickly select, import, and transform data with SQL and over 300 built-in transformations without writing code. Generate intuitive data quality reports to detect anomalies across data types, and estimate model performance. Scale to process petabytes of data.
Benefits of SageMaker Data Wrangler
How it works
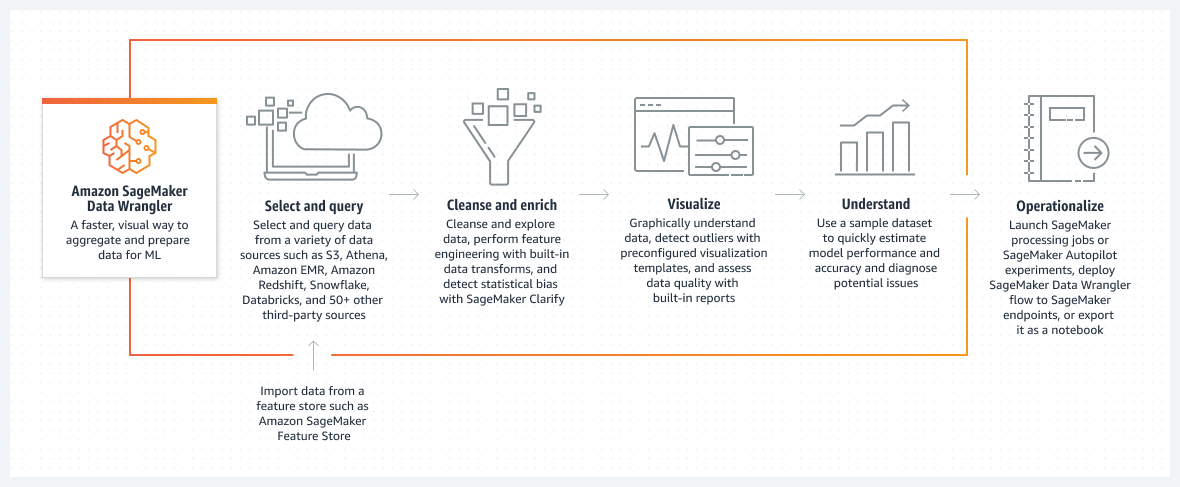
How it works

Title 1: Amazon SageMaker Data Wrangler
Description text: A faster, visual way to aggregate and prepare data for ML
Title 2: Select and query
Description text: Select and query data from a variety of data sources such as Amazon S3, Athena, Amazon EMR, Amazon Redshift, Snowflake, Databricks, and 50+ other third-party sources
Sub Description: Import data from a feature store such as Amazon SageMaker Feature Store
Title 3: Cleanse and enrich
Description text: Cleanse and explore data, preform feature engineering with built-in data transforms, and detect statistical bias with SageMaker Clarify
Title 4: Visualize
Description text: Graphically understand data, detect outliers with preconfigured visualization templates, and assess data quality with built-in reports
Title 5: Understand
Description text: Use a sample dataset to quickly estimate model performance and accuracy and diagnose potential issues
Title 6: Operationalize
Description text: Launch SageMaker processing jobs or SageMaker Autopilot experiments, deploy SageMaker Data Wrangler flow to SageMaker endpoints, or export it as a notebook.
Access, select, and query data faster
With SageMaker Data Wrangler, you can quickly access tabular, text, and image data from Amazon services such as S3, Athena, Redshift, and 50+ third-party sources. You can select data with visual query builder, write SQL queries, or import data data directly in various formats such as CSV, and Parquet.

Generate data insights and understand data quality
SageMaker Data Wrangler provides a data quality and insights report that automatically verifies data quality (such as missing values, duplicate rows, and data types) and helps detect anomalies (such as outliers, class imbalance, and data leakage) in your data. Once you can effectively verify data quality, you can quickly apply domain knowledge to process datasets for ML model training.

Understand your data with visualizations
SageMaker Data Wrangler helps you understand your data through robust built-in visualization templates such as histograms, scatter plots, feature importance, and correlations. Accelerate data exploratory with intuitive data quality reports that detect anomalies across data types and provide recommendations to improve data quality.

Transform data more efficiently
SageMaker Data Wrangler offers over 300 prebuilt PySpark transformations and a natural language interface to prepare tabular, timeseries, text and image data without coding. Common use cases such vectorize text, featurize datetime, encoding, balancing data, or image augmentation are covered. You can also author custom transformations in PySpark, SQL, and Pandas or use natural language interface to generate code. A built-in library of code snippets simplifies writing custom transformations.

Understand the predictive power of your data
SageMaker Data Wrangler provides a Quick Model analysis to estimate your data's predictive power. You get estimated model accuracy, feature importance, and a confusion matrix to help you validate your data quality before training models.

Automate and deploy ML data preparation workflows
SageMaker Data Wrangler lets you scale to prepare petabyte of data without coding PySpark or spinning up clusters. Launch processing jobs directly from the UI, or integrate data prep into ML workflows by exporting data to SageMaker Feature Store or integrating with SageMaker Pipelines. You can also export data flows as Jupyter notebooks or Python script for programmatic replication of your data preparation steps.

Customers
"At INVISTA, we are driven by transformation and look to develop products and technologies that benefit customers around the globe. We see ML as a way to improve the customer experience. But, with datasets that span hundreds of millions of rows, we needed a solution to help us prepare data, and develop, deploy, and manage ML models at scale. With Amazon SageMaker Data Wrangler, we can now interactively select, clean, explore, and understand our data effectively, empowering our data science team to create feature engineering pipelines that can scale effortlessly to datasets that span hundreds of millions of rows. With Amazon SageMaker Data Wrangler, we can operationalize our ML workflows faster."
Caleb Wilkinson, Former Lead Data Scientist, INVISTA
"Using ML, 3M is improving tried-and-tested products, like sandpaper, and driving innovation in several other spaces, including healthcare. As we plan to scale ML to more areas of 3M, we see the amount of data and models growing rapidly—doubling every year. We are enthusiastic about the new SageMaker features because they will help us scale. Amazon SageMaker Data Wrangler makes it much easier to prepare data for model training, and Amazon SageMaker Feature Store will eliminate the need to create the same model features over and over. Finally, Amazon SageMaker Pipelines will help us automate data prep, model building, and model deployment into an end-to-end workflow so we can speed time to market for our models. Our researchers are looking forward to taking advantage of the new speed of science at 3M."
David Frazee, Former Technical Director, 3M Corporate Systems Research Lab
"Amazon SageMaker Data Wrangler enables us to hit the ground running to address our data preparation needs with a rich collection of transformation tools that accelerate the process of ML data preparation needed to take new products to market. In turn, our clients benefit from the rate at which we scale deployed models, enabling us to deliver measurable, sustainable results that meet the needs of our clients in a matter of days rather than months."
Frank Farrall, Principal, AI Ecosystems and Platforms Leader, Deloitte
"As an AWS Premier Consulting Partner, our engineering teams are working very closely with AWS to build innovative solutions to help our customers continuously improve the efficiency of their operations. ML is the core of our innovative solutions, but our data preparation workflow involves sophisticated data preparation techniques which, as a result, take a significant amount of time to become operationalized in a production environment. With Amazon SageMaker Data Wrangler, our data scientists can complete each step of the data preparation workflow, including data selection, cleansing, exploration, and visualization, which helps us accelerate the data preparation process and easily prepare our data for ML. With Amazon SageMaker Data Wrangler, we can prepare data for ML faster."
Shigekazu Ohmoto, Senior Corporate Managing Director, NRI Japan
"As our footprint in the population health management market continues to expand into more health payors, providers, pharmacy benefit managers, and other healthcare organizations, we needed a solution to automate end-to-end processes for data sources that feed our ML models, including claims data, enrollment data, and pharmacy data. With Amazon SageMaker Data Wrangler, we can now accelerate the time it takes to aggregate and prepare data for ML using a set of workflows that are easier to validate and reuse. This has dramatically improved the delivery time and quality of our models, increased the effectiveness of our data scientists, and reduced data preparation time by nearly 50%. In addition, SageMaker Data Wrangler has helped us save multiple ML iterations and significant GPU time, speeding the entire end-to-end process for our clients as we can now build data marts with thousands of features including pharmacy, diagnosis codes, ER visits, inpatient stays, as well as demographic and other social determinants. With SageMaker Data Wrangler, we can transform our data with superior efficiency for building training datasets, generate data insights on datasets prior to running ML models, and prepare real-world data for inference/predictions at scale.”
Lucas Merrow, CEO, Equilibrium Point IoT