



什么是机器学习中的提升方法?
提升是机器学习中使用的一种方法,用于减少预测数据分析中的错误。数据科学家针对标记数据训练机器学习软件(也称为机器学习模型),以猜测未标记数据。单个机器学习模型可能会出现预测错误,具体取决于训练数据集的准确性。例如,如果仅针对白猫图像训练猫识别模型,则可能偶尔会错误地识别出黑猫。提升方法将会尝试通过循序训练多个模型来提高整个系统的准确性,以克服此问题。
为什么提升方法非常重要?
提升方法可以通过将多个弱学习器转换为单个强学习模型,来提高机器模型的预测准确性和性能。机器学习模型可以是弱学习器,也可以是强学习器:
弱学习器
弱学习器的预测准确性很低,与随机猜测相似。它们易于过度拟合 - 也就是说,它们无法对与原始数据集差异太大的数据进行分类。例如,如果您训练模型将猫识别为尖耳朵的动物,则该模型可能就无法识别耳朵卷曲的猫。
强学习器
强学习器的预测准确性较高。提升方法可将包含多个弱学习器的系统转换为单个强学习系统。例如,为了识别猫的图像,它将结合一个猜测尖耳朵的弱学习器和另一个猜测猫形眼睛的学习器。在分析动物图像是否存在尖耳朵后,该系统还会再次分析该图像是否存在猫形眼睛。这将提高该系统的总体准确性。
提升方法的工作原理是什么?
为了解提升方法的工作原理,让我们介绍一下机器学习模型如何制定决策。尽管在实施过程中有很多变化,但数据科学家经常将提升方法与决策树算法配合使用:
决策树
决策树是机器学习中的数据结构,它根据数据集的特征将数据集划分为越来越小的子集。其理念是决策树将反复拆分数据,直到仅剩下一个类。例如,决策树可能会提出一系列答案为是或否的问题,然后在每一步将数据划分为各个类别。
提升集成方法
提升方法可以通过将几个弱决策树按顺序组合起来,创建一个集成模型。它将为各个树的输出结果分配权重。然后,它将为来自第一个决策树的不正确分类赋予更高权重,并输入到下一个树。经过多次循环后,提升方法会将这些弱规则组合成一个强大的预测规则。
提升方法与装袋方法 (Bagging) 对比
提升方法和装袋方法是两种用于提高预测准确性的常见集成方法。这两种学习方法之间的主要区别在于训练方法。在装袋方法中,数据科学家通过在多个数据集上一次训练多个弱学习器中的数个,来提高这些弱学习器的准确性。相比之下,提升方法是一个接一个地训练弱学习器。
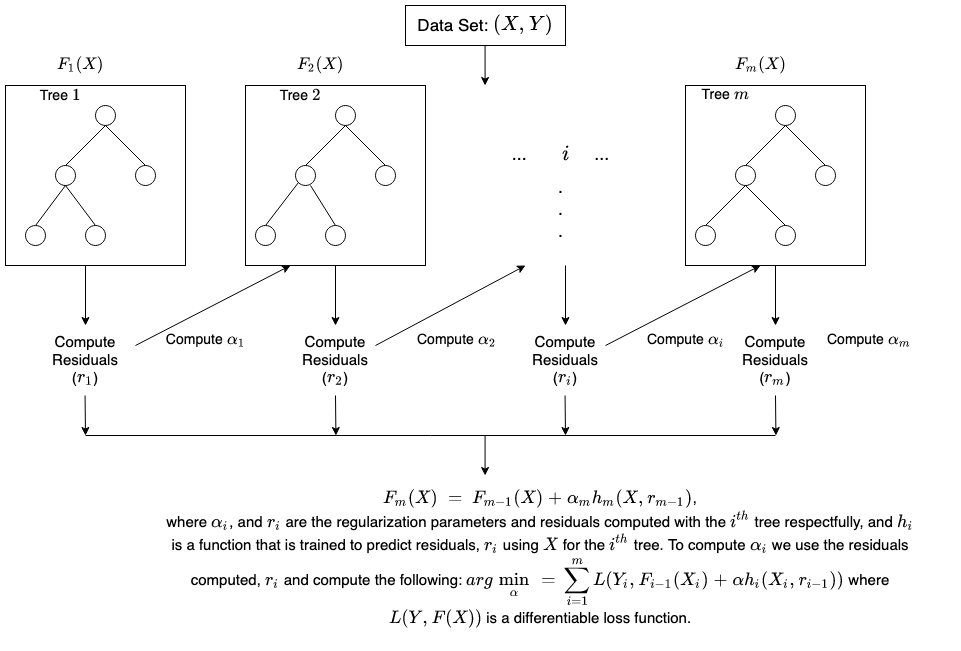
如何在提升方法中完成训练?
训练方法因提升过程(称为提升算法)的类型而异。但是,算法会采用以下一般步骤来训练提升模型:
步骤 1
提升算法为每个数据样本分配相等的权重。它会将数据馈送到第一个机器模型中,称为基本算法。基本算法针对每个数据样本进行预测。
步骤 2
提升算法将评估模型预测,并提高具有更显著错误的样本的权重。它还将根据模型性能分配权重。输出精准预测的模型将对最终决策具有很大的影响力。
步骤 3
该算法会将加权数据传递给下一个决策树。
步骤 4
该算法将重复步骤 2 和步骤 3,直到训练错误的实例数量低于某一阈值为止。
提升方法有哪些类型?
以下是提升方法的三种主要类型:
自适应提升方法
自适应提升方法 (AdaBoost) 是最早开发的提升方法之一。它会在提升过程的每次迭代中适应并尝试自我更正。
AdaBoost 首先会为每个数据集赋予相同权重。然后,它会在每个决策树之后自动调整数据点的权重。它将为错误分类的项目赋予更高权重,以便在下一轮更正它们。它将重复该过程,直到残差或实际值与预测值之差低于可接受的阈值为止。
您可以将 AdaBoost 与许多预测器配合使用,它通常不像其他提升算法那样敏感。当特征或高数据维度之间存在相关性时,此方法效果不佳。总体而言,AdaBoost 是一种适用于分类问题的增强方法类型。
梯度提升方法
梯度提升方法 (GB) 也是一种顺序训练技术,因此在这方面与 AdaBoost 相似。AdaBoost 与 GB 之间的区别在于,GB 不会为错误分类的项目赋予更高权重。相反,GB 软件将通过按顺序生成基本学习器来优化损失函数,使得当前基本学习器总是比前一个更有效。这种方法将尝试在最初就生成准确结果,而不是像 AdaBoost 那样在整个过程中不断更正错误。因此,GB 软件可以得出更准确的结果。梯度提升方法可以帮助解决基于分类和回归的问题。
极限梯度提升方法
极限梯度提升方法 (XGBoost) 可以通过多种方式提高梯度提升方法的计算速度和规模。XGBoost 可以使用 CPU 上的多个核心,从而可在训练过程中并行进行学习。它是一种提升算法,可以处理广泛的数据集,使其对于大数据应用程序很有吸引力。XGBoost 的关键特征包括并行化、分布式计算、缓存优化和核外处理。
提升方法有哪些好处?
提升方法可以带来以下主要好处:
易于实施
提升方法具有易于理解和易于解释的算法,可以从错误中学习。这些算法不需要任何数据预处理,并且它们具有内置例程来处理丢失的数据。此外,大多数语言都有内置库,可以通过许多参数来实施提升算法,这些参数可对性能进行微调。
减少偏差
偏差是指机器学习结果中存在不确定性或不准确性。提升算法以顺序方法将多个弱学习器组合在一起,以迭代方式改进观察结果。此方法有助于减少机器学习模型中常见的高偏差。
计算效率高
提升算法优先考虑可在训练期间提高预测准确性的特征。它们可以帮助减少数据属性,并有效处理大型数据集。
提升方法会带来哪些挑战?
以下是提升模式的常见限制:
易受异常值数据影响
提升模型容易受到异常值或与数据集其余部分不同的数据值的影响。因为每个模型都会尝试更正其前身的错误,所以异常值可能会显著扭曲结果。
实时实施
您可能还会发现,使用提升方法进行实时实施很有挑战性,因为该算法比其他过程更复杂。提升方法具有很强的适应性,因此您可以使用多种模型参数,这些参数会立即影响模型的性能。
AWS 如何帮助您使用提升方法?
AWS 联网服务旨在为企业提供以下内容:
Amazon SageMaker
Amazon SageMaker 汇集了一系列专为机器学习而构建的功能。您可以使用它来快速准备、构建、训练和部署高质量的机器学习模型。
Amazon SageMaker Canvas
Amazon SageMaker Canvas 可以消除构建机器学习模型的繁重工作,并可帮助您根据数据自动构建和训练模型。借助 SageMaker Canvas,您可以提供一个表格数据集,并选择要预测的目标列,可以是数字或类别。SageMaker Autopilot 将自动探索不的解决方案,以找到最佳模型。然后,只需单击一下,即可将模型直接部署到生产环境中,或使用 Amazon SageMaker Studio 迭代推荐的解决方案,以进一步提高模型质量。
Amazon SageMaker 模型监控器
Amazon SageMaker 模型训练可以通过实时捕获训练指标,以及在检测到错误时发送提示,来轻松优化机器学习模型。这可以帮助您立即纠正不准确的模型预测,如对图像的错误识别。
Amazon SageMaker 提供了训练大型深度学习模型和数据集的快捷、简单的方法。SageMaker 分布式训练库可以更快地训练大型数据集。
立即创建 AWS 账户,开始使用 Amazon SageMaker。