¿En qué consiste el entrenamiento de modelos de SageMaker?
El entrenamiento de modelos de Amazon SageMaker reduce el tiempo y el costo que lleva entrenar y ajustar los modelos de machine learning (ML) a escala sin necesidad de administrar la infraestructura. Puede aprovechar la infraestructura de computación de ML de mayor rendimiento disponible en la actualidad, y Amazon SageMaker IA puede escalar o desescalar verticalmente la infraestructura de forma automática, desde una a miles de GPU. Para entrenar modelos de aprendizaje profundo más rápido, SageMaker AI lo ayuda a seleccionar y refinar conjuntos de datos en tiempo real. Las bibliotecas de entrenamiento distribuidas de SageMaker pueden dividir automáticamente modelos grandes y conjuntos de datos de entrenamiento en instancias de GPU de AWS, o bien puede utilizar bibliotecas de terceros, como DeepSpeed, Horovod o Megatron. Entrene modelos fundacionales (FM) durante semanas y meses sin interrupciones mediante la supervisión y reparación automáticas de los clústeres de entrenamiento.
Beneficios de un entrenamiento rentable
Entrene modelos a escala
Trabajos de entrenamiento totalmente administrados
Los trabajos de entrenamiento de Amazon SageMaker brindan una experiencia de usuario completamente administrada para el entrenamiento de grandes modelos fundacionales distribuidos, lo que elimina la complejidad y las tareas operativas asociadas con la administración de la infraestructura que no marcan la diferencia. Los trabajos de entrenamiento de SageMaker activan automáticamente un clúster de entrenamiento distribuido y flexible, supervisan la infraestructura y se recuperan automáticamente de los errores para garantizar una experiencia fluida. Una vez finalizado el proceso, SageMaker reduce el clúster y se factura el tiempo neto de entrenamiento. Además, con los trabajos de entrenamiento de SageMaker, tiene la flexibilidad de elegir el tipo de instancia adecuado que mejor se adapte a cada carga de trabajo específica (por ejemplo, preentrenar un modelo de lenguaje de gran tamaño [LLM] en un clúster P5 o ajustar un LLM de código abierto en instancias p4d) para optimizar aún más el presupuesto de entrenamiento. Además, los trabajos de entrenamiento de SageMaker ofrecen una experiencia de usuario uniforme para equipos de machine learning con distintos niveles de experiencia técnica y tipos de carga de trabajo.
SageMaker HyperPod
Amazon SageMaker HyperPod es una infraestructura diseñada específicamente para administrar de manera eficiente los clústeres de computación a fin de escalar el desarrollo del modelo fundacional (FM). Permite técnicas avanzadas de entrenamiento de modelos, control de infraestructura, optimización del rendimiento y mejora de la observabilidad de los modelos. SageMaker HyperPod viene preconfigurado con bibliotecas de entrenamiento distribuido de SageMaker, lo que permite dividir automáticamente modelos y conjuntos de datos de entrenamiento entre las instancias del clúster de AWS. Esto optimiza el uso eficiente de la infraestructura de computación y red del clúster. Posibilita un entorno de entrenamiento más flexible ya que detecta, diagnostica y se recupera automáticamente de los errores de hardware, lo que permite entrenar de forma continua los FM durante meses sin interrupciones y así reducir el tiempo de entrenamiento hasta en un 40 %.
Entrenamiento distribuido de alto rendimiento
SageMaker AI agiliza la realización del entrenamiento distribuido mediante la división automática de modelos y conjuntos de datos de entrenamiento en los aceleradores de AWS. Ayuda a optimizar el trabajo de entrenamiento para la topología del clúster y la infraestructura de red de AWS. También optimiza los puntos de control del modelo con las recetas mediante la optimización de la frecuencia con la que se guardan los puntos de control, lo que garantiza una sobrecarga mínima durante el entrenamiento. Con las recetas, los científicos de datos y los desarrolladores de todos los niveles se benefician de un rendimiento de vanguardia y, al mismo tiempo, comienzan a entrenar y refinar rápidamente los modelos de IA generativa disponibles al público, incluidos Llama 3.1 405B, Mixtral 8x22B y Mistral 7B. Las recetas incluyen una pila de entrenamiento que AWS ha probado, lo que elimina semanas de tedioso trabajo de prueba de diferentes configuraciones de modelos. Es posible alternar entre instancias basadas en GPU e instancias basadas en AWS Trainium con un cambio de una línea en la receta y habilitar puntos de control automatizados del modelo para aumentar la resiliencia del entrenamiento. Además, ejecute cargas de trabajo en producción con la característica de entrenamiento de SageMaker que prefiera.
Herramientas integradas para la interactividad y el monitoreo
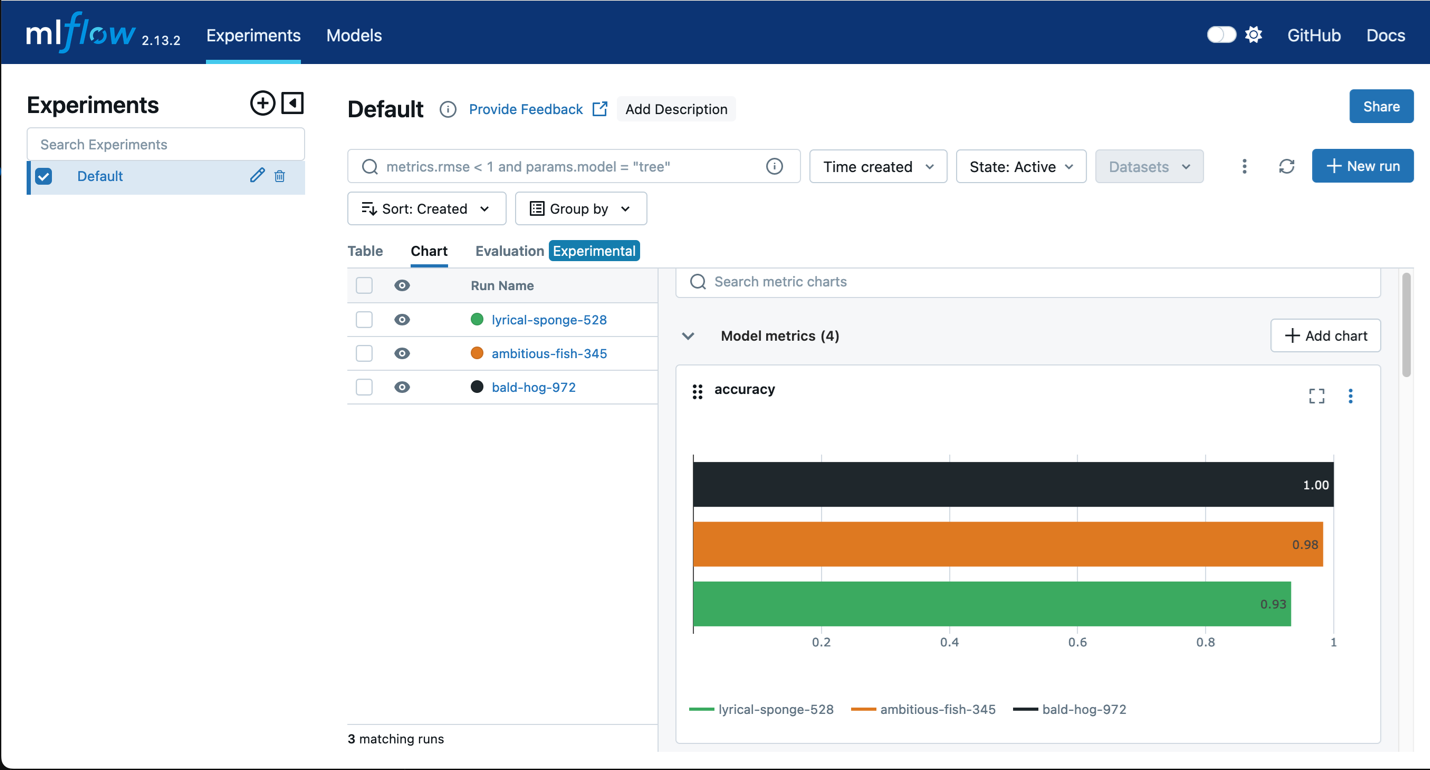
Amazon SageMaker con MLflow
Utilice MLflow gracias con el entrenamiento de SageMaker para capturar parámetros de entrada, configuraciones y resultados, lo que le ayudará a identificar rápidamente los modelos con mejor rendimiento para su caso de uso. La interfaz de usuario de MLflow le permite analizar los intentos de entrenamiento del modelo y registrar fácilmente los modelos candidatos para la producción en un solo paso.
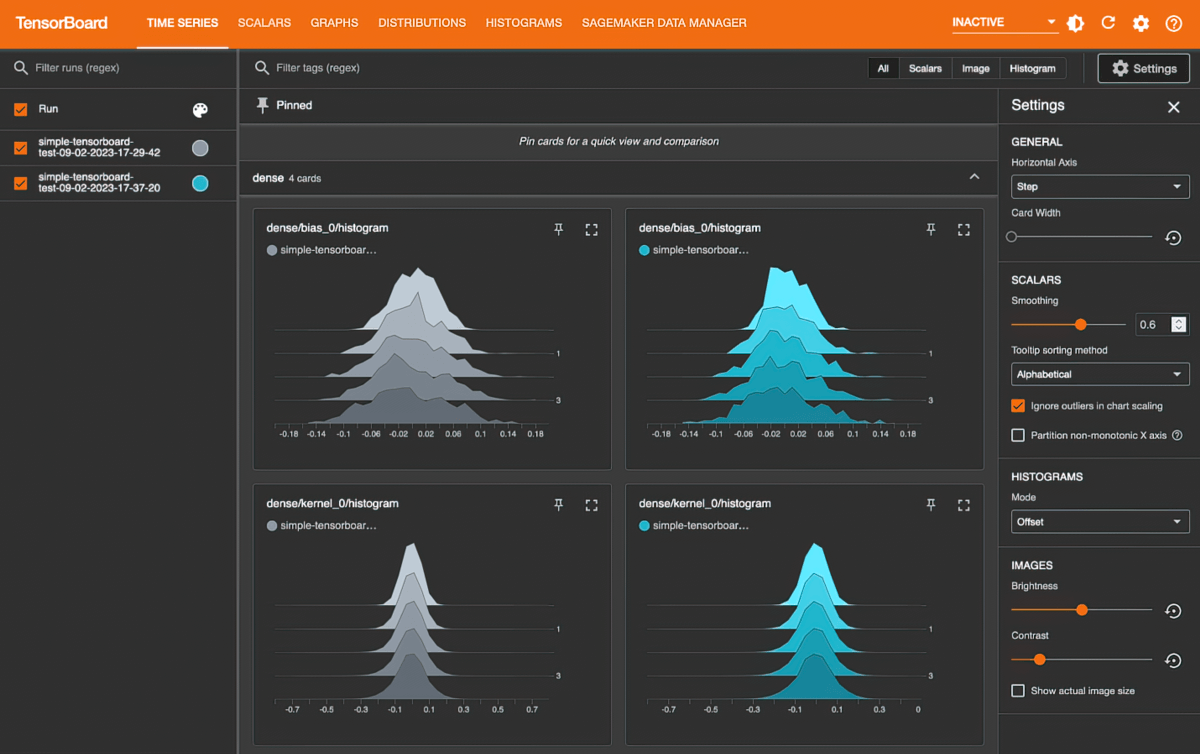
Amazon SageMaker con TensorBoard
Amazon SageMaker con TensorBoard lo ayuda a ahorrar tiempo de desarrollo al visualizar la arquitectura del modelo para identificar y solucionar problemas de convergencia, como la pérdida de validación, la no convergencia o la desaparición de gradientes.
Recursos
Novedades
- Fecha (de más reciente a más antigua)