Amazon SageMaker 모델 훈련이란 무엇인가요?
Amazon SageMaker 모델 훈련에서는 인프라를 관리할 필요가 없으므로 기계 학습(ML) 모델을 대규모로 훈련하고 튜닝하는 데 필요한 시간과 비용이 절감됩니다. 현재 시중에 나와 있는 최고 성능의 ML 컴퓨팅 인프라를 활용할 수 있으며, Amazon SageMaker AI는 인프라를 GPU 1개에서 수천 개까지 자동으로 스케일 업 또는 스케일 다운할 수 있습니다. 딥 러닝 모델을 더 빠르게 훈련시키기 위해 SageMaker AI는 실시간으로 데이터세트를 선택하고 조정할 수 있도록 도와줍니다. SageMaker 분산 훈련 라이브러리를 사용하여 대규모 모델 및 훈련 데이터 세트를 여러 AWS GPU 인스턴스에 자동으로 분할하거나, DeepSpeed, Horovod 또는 Megatron과 같은 서드 파티 라이브러리를 사용할 수 있습니다. 훈련 클러스터를 자동으로 모니터링하고 복구하여 운영 중단 없이 몇 주 또는 몇 달 동안 파운데이션 모델(FM)을 훈련합니다.
비용 효율적인 훈련의 이점
대규모 모델 학습
완전 관리형 훈련 작업
SageMaker 훈련 작업은 대규모 분산 FM 교육을 위한 완전 관리형 사용자 환경을 제공하므로 인프라 관리의 획일적이고 부담스러운 작업을 없앨 수 있습니다. SageMaker 훈련 작업은 복원력이 뛰어난 분산 훈련 클러스터를 자동으로 가동하고 인프라를 모니터링하며 장애를 자동으로 복구하여 원활한 훈련 환경을 보장합니다. 훈련이 완료되면 SageMaker가 클러스터를 스핀다운하며, 순 훈련 시간에 대한 요금이 청구됩니다. 또한 SageMaker 훈련 작업을 사용하면 개별 워크로드에 가장 적합한 인스턴스 유형을 유연하게 선택하여(예를 들어, P5 클러스터에서 대규모 언어 모델(LLM)을 사전 훈련하거나 p4d 인스턴스에서 오픈 소스 LLM을 미세 조정) 훈련 예산을 추가로 최적화할 수 있습니다. 또한 SagerMaker 훈련 작업은 ML 팀 전반에서 다양한 수준의 기술 전문 지식과 다양한 워크로드 유형을 포함하는 일관된 사용자 환경을 제공합니다.
SageMaker HyperPod
Amazon SageMaker HyperPod는 컴퓨팅 클러스터를 효율적으로 관리하여 파운데이션 모델(FM) 개발을 확장하기 위해 특별히 설계된 인프라입니다. 이 인프라를 통해 고급 모델 훈련 기법, 인프라 제어, 성능 최적화 및 향상된 모델 관찰성이 가능해집니다. SageMaker HyperPod는 SageMaker 분산 훈련 라이브러리로 사전 구성되기 때문에 모델 및 훈련 데이터세트를 AWS 클러스터 인스턴스 간에 자동으로 분할하여 클러스터의 컴퓨팅 및 네트워크 인프라를 효율적으로 활용할 수 있도록 합니다. 또한 하드웨어 결함을 자동으로 감지, 진단 및 복구하여 복원력이 높은 환경을 제공하므로 중단 없이 몇 개월 동안 지속적으로 FM을 훈련할 수 있으므로 훈련 시간이 40%까지 감소됩니다.
고성능 분산 훈련
SageMaker AI를 사용하면 모델과 훈련 데이터세트를 여러 AWS 액셀러레이터에 자동으로 분할하여 분산 훈련을 더 빠르게 수행할 수 있습니다. 따라서 AWS 네트워크 인프라 및 클러스터 토폴로지에 대한 훈련 작업을 최적화할 수 있습니다. 또한 체크포인트 저장 빈도를 최적화하여 레시피를 통해 모델 체크포인팅을 간소화하고 훈련 중 오버헤드를 최소화합니다. 레시피를 사용하면 기술 분야와 관계없이 데이터 과학자와 개발자는 Lama 3.1 405B, Mixtral 8x22B 및 Mistral 7B를 비롯하여 공개적으로 사용 가능한 생성형 AI 모델을 빠르게 훈련시키고 미세 조정할 수 있는 동시에 최첨단 성능의 이점을 활용할 수 있습니다. 레시피에는 AWS에서 테스트한 훈련 스택이 포함되어 있어 다양한 모델 구성을 테스트하는 데 걸리는 몇 주 동안의 지루한 작업을 없앨 수 있습니다. 한 줄의 레시피 변경으로 GPU 기반 인스턴스와 AWS Trainium 기반 인스턴스 간에 전환하고 자동화된 모델 체크포인트 지정을 활성화하여 훈련 복원력을 개선할 수 있습니다. 또한 선택한 SageMaker 훈련 기능으로 프로덕션 환경에서 워크로드를 실행할 수 있습니다.
상호 작용 및 모니터링을 위한 기본 제공 도구
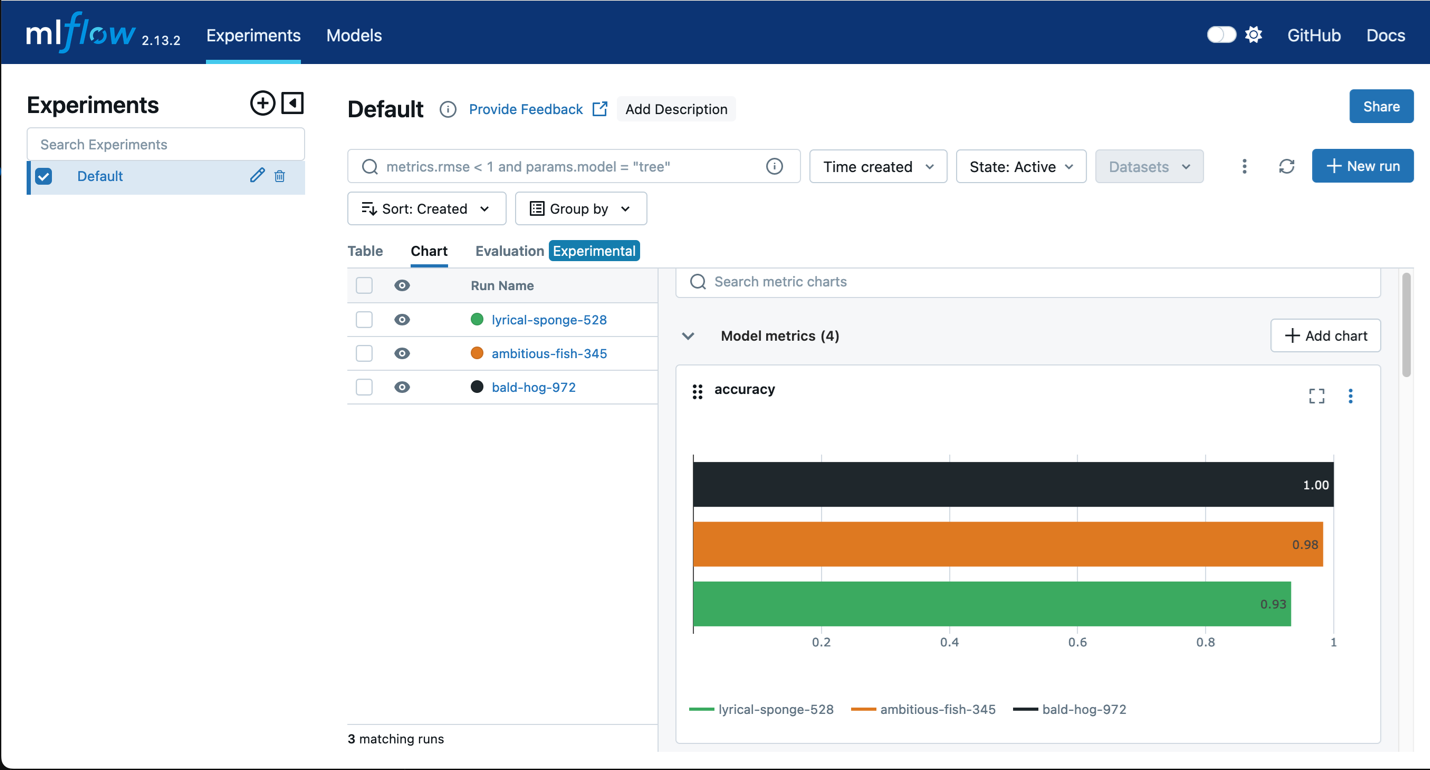
MLflow가 포함된 Amazon SageMaker
SageMaker 훈련에 MLflow를 사용해 입력 파라미터, 구성 및 결과를 캡처하면 사용 사례에 가장 적합한 모델을 신속하게 식별하도록 도와줍니다. MLflow UI를 사용하여 한 단계만에 모델 훈련 시도를 분석하고 프로덕션에 사용할 후보 모델을 손쉽게 등록할 수 있습니다.
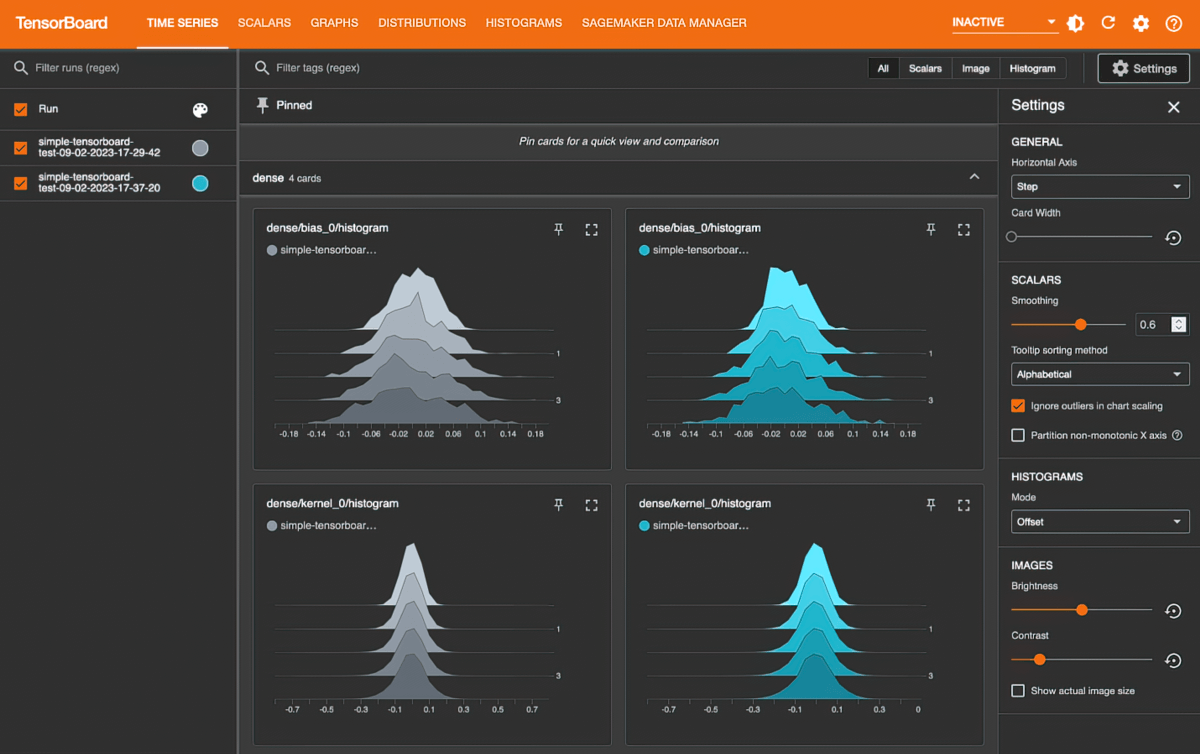
TensorBoard가 포함된 Amazon SageMaker
Amazon SageMaker with TensorBoard는 모델 아키텍처를 시각화하여 수렴되지 않는 검증 손실, 소실되는 그래디언트 등의 컨버전스 문제를 식별하고 해결함으로써 개발 시간을 절약하는 데 도움을 줍니다.