テキスト読み上げについて学びます。
テキスト読み上げ (TTS、Text-to-speech) は、書かれた言葉を聞き取れる音声に変換する技術です。AI 音声ジェネレーターは、ユーザーが画面上の文字を読むことができない (または都合が悪い) 場合に、ユーザーとやり取りします。テキスト読み上げテクノロジーは、アプリケーションや情報を新しい方法で使用できるようにすることで、画面上のテキストを読むことができないユーザーのアクセシビリティを向上させます。
テキスト読み上げテクノロジーは、この数十年間で進歩してきました。深層学習により、間隔、速さ、発音、抑揚の変化を含め、ごく自然な響きの読み上げが可能になっています。今日、コンピュータで生成された音声はさまざまなユースケースで使用されており、ユーザーインターフェイスのいたるところに浸透しつつあります。ニュースリーダー、ゲーム、公共広告システム、e ラーニング、テレフォニー、IoT のアプリおよびデバイス、パーソナルアシスタントがありますが、これらはほんの出発点でしかありません。
テキスト読み上げの利点は何ですか?
音声合成により、アプリケーションにさらにアクセスしやすくなり、ユーザーは画面に集中することなく情報を利用し、理解できるようになります。以下に、テキスト読み上げテクノロジーを利用する主な利点を簡単にまとめます。
アクセシビリティ
テキスト読み上げは、さまざまなコミュニケーションスタイルや好みに応え、より多くのユーザーがデジタルコンテンツにアクセスできるようにします。視覚障害、識字能力の問題、年齢、その他の健康上の問題で文字を読むことができないユーザーのアクセシビリティが向上します。支援技術として、情報を入手して包括性を確保するための代替手段を提供します。
高度な学習
テキスト読み上げはオンラインマテリアルに適用され、e ラーニングを促進しています。視覚と聴覚の両方を使って学習することで、理解力、想起力、語彙力、モチベーション、自信が向上します。このテクノロジーでデジタルテキストを読み上げることで、語学学習者は単語やフレーズの正確な発音方法を理解できます。また、テキストを聞くことで、語彙の定着と文の構造の理解も強化されます。
モビリティと自由
テキスト読み上げにより、あらゆるデジタルコンテンツをマルチメディア体験に変えることができます。ニュースやブログの記事、PDF ドキュメントなどを、移動中や作業中に聞くことができます。ユーザーはハンズフリーでコンテンツを柔軟に利用できるため、生産性が向上します。
エンゲージメントとユーザーエクスペリエンス
TTS テクノロジーを使用することで、ユーザーは長い記事やレポート、本を積極的に読むようになります。より多くの文書コンテンツに短時間でアクセスできるため、コンテンツの保持率が向上し、結果として訪問者数やサイト滞在時間などのアプリケーション指標が向上します。カスタマージャーニーを強化することで、より多くのコンバージョンを獲得できます。
迅速性と手頃な料金
クラウドコンピューティングにより、テキスト読み上げを迅速かつ簡単に実装できるようになりました。クラウドは規模の経済性に優れるため、統合も安価に行えます。利用を開始するために前払い料金や最低月額料金を支払う必要はなく、ユーザーが機能にアクセスした場合にのみ料金が発生します。
テキスト読み上げテクノロジーのユースケースにはどのようなものがありますか?
音声を使用してコミュニケーションを行うアプリケーションが、日々一般的になってきました。テキスト読み上げソリューションを使用すると、ウェブサイト、モバイルアプリ、電子書籍、e ラーニングツール、オンラインドキュメントが、まさに独自の「声」を持てるようになります。ユースケースの例をいくつか以下に示します。
オーディオパブリッシング
出版者とコンテンツ所有者は、テキスト読み上げを使用して、本、記事、その他の文書マテリアルをすばやく手頃な料金で音声に変換できます。e ラーニングやトレーニングのユースケースで、既存のテキストを幅広い学習者向けに変換できます。コンテンツをより効果的で低コストのフォーマットに変換して、複数の言語で展開できます。
カスタマーサービス
TTS システムは、インタラクティブコールセンターの品質を高め、通信アプリケーションをサポートします。ユーザーの要求に応じてデジタルテキストを読み上げる、より優れたチャットボットと AI アシスタントを構築できます。また、インタラクティブ応答メカニズムや自動電話システムを支える重要なテクノロジーでもあります。自動化されたカスタマーサービスインタラクションを、単調なフレーズで返答するだけでなく親身な対応が可能な会話型応答に拡張することで、顧客満足度を向上させることができます。
メディアとエンターテインメント
TTS テクノロジーを使用して、ビデオ、アニメーション、インタラクティブゲームのナレーションを生成できます。これにより、メディアのプリプロダクションと開発におけるコストを削減し、効率を向上させることができます。また、ゲームやインタラクティブアプリでのプレイヤーのアクションに基づいて、リアルタイムのナレーションや動的な解説を行うことも可能です。さらに、テキスト読み上げツールを使用して、バーチャルリアリティ (VR、Virtual Reality) 環境で没入感のあるオーディオコンテンツを配信することもできます。
医療
医療で TTS テクノロジーを使用することで、患者とのコミュニケーションを促進すると共に、医療従事者の不足に対処できます。音声インターフェイスを備えた生成 AI 搭載アプリケーションは、患者の質問や意図の解釈、患者のトリアージ、自然な音声での応答を行えます。また、予約から治療管理のサポート、投薬リマインダーまで、患者に画面を読ませることなくすべてを行うことができます。
テキスト読み上げはどのように機能しますか?
テキスト読み上げシステムは、強力な人工知能 (AI) と機械学習 (ML) モデルを使用して、テキストから話し言葉を生成します。各モデルはディープニューラルネットワーク、つまり人間の脳のようにリンクして連携するコンピューティングノード上で実行されます。ディープニューラルネットワークは、さまざまな言語、アクセント、ピッチ、音量の音声データを使ってトレーニングされます。トレーニング中、オーディオクリップと、それに対応する文字起こしされたテキストの両方が AI モデルに渡されます。このモデルは、書き言葉と話し言葉の相関関係とパターンを識別します。その知識を使って新しいテキストを分析し、音声に変換します。
このプロセスは、以下のように機能します。
テキストを時系列特徴量に変換する
ニューラルネットワークは最初に入力テキストを受け取り、それを時系列特徴量に変換します。これらの特徴量は時間の経過に伴う音声の詳細な特性 (ピッチ、リズム、トーンなど) を表します。一般的な特徴量は次のとおりです。
- メルスペクトログラム: 音の周波数が時間と共にどのように変化するかを示します。
- F0 周波数: ピッチまたは基本音声周波数を表します。
このシステムは、特定の音をどのように発音し、強調すべきかといった言語的特徴も考慮しながら、音声が自然に聞こえるようにタイミングを調整します。例えば、「hello」という単語は、最初の音が短く、その後に長い 2 番目の音が続きます。
時系列特徴量を音声に変換する
次のステップでは、これらの特徴量を人間が話しているような音声に変換します。ニューラルネットワークは特徴量を処理して、滑らかで自然な音声を合成します。高度なテキスト読み上げテクノロジーにより、次のような特徴量が得られます。
- 音量調整 (ささやき声にも対応)
- ピッチの高低
- 速度の高低
- 複数の言語とアクセント
- 複数の話し方 (ブランドに合わせてカスタマイズされた音声や話し方など)
テキスト読み上げテクノロジーはどのように実装されますか?
組織は、テキスト読み上げテクノロジーを 2 つの方法で実装しています。
セルフマネージド
AI/ML チームは、専用のテキスト読み上げ AI モデルを使用し、独自のデータに基づいてこのモデルをさらにトレーニングします。その後、このモデルは本番環境にデプロイされ、さまざまなアプリケーションで使用されます。このプロセスにはかなりの時間とコストがかかります。AI モデルの維持と管理も組織が行います。このアプローチでは、テキスト読み上げを本番環境で使用できるようになるまでに数か月かかることがあります。
完全マネージド型
完全マネージド型のテキスト読み上げでは、API を使用してコードに統合できるサードパーティモデルを使用します。モデルの管理、トレーニング、維持はすべて、サードパーティプロバイダーが行います。テキストコンテンツを入力としてモデルに渡すと、出力としてオーディオファイルが生成されます。また、ウェブページやその他の動的に変化するコンテンツを入力として受け取り、対応する出力をリアルタイムで生成するように設定することもできます。
完全マネージド型のテキスト読み上げサービスは費用対効果に優れ、使いやすく統合も簡単です。使用するのに ML/AI の専門知識は必要ありません。開発者はわずか数時間でこれらの AI 音声ジェネレーターを既存のアプリケーションに統合できます。
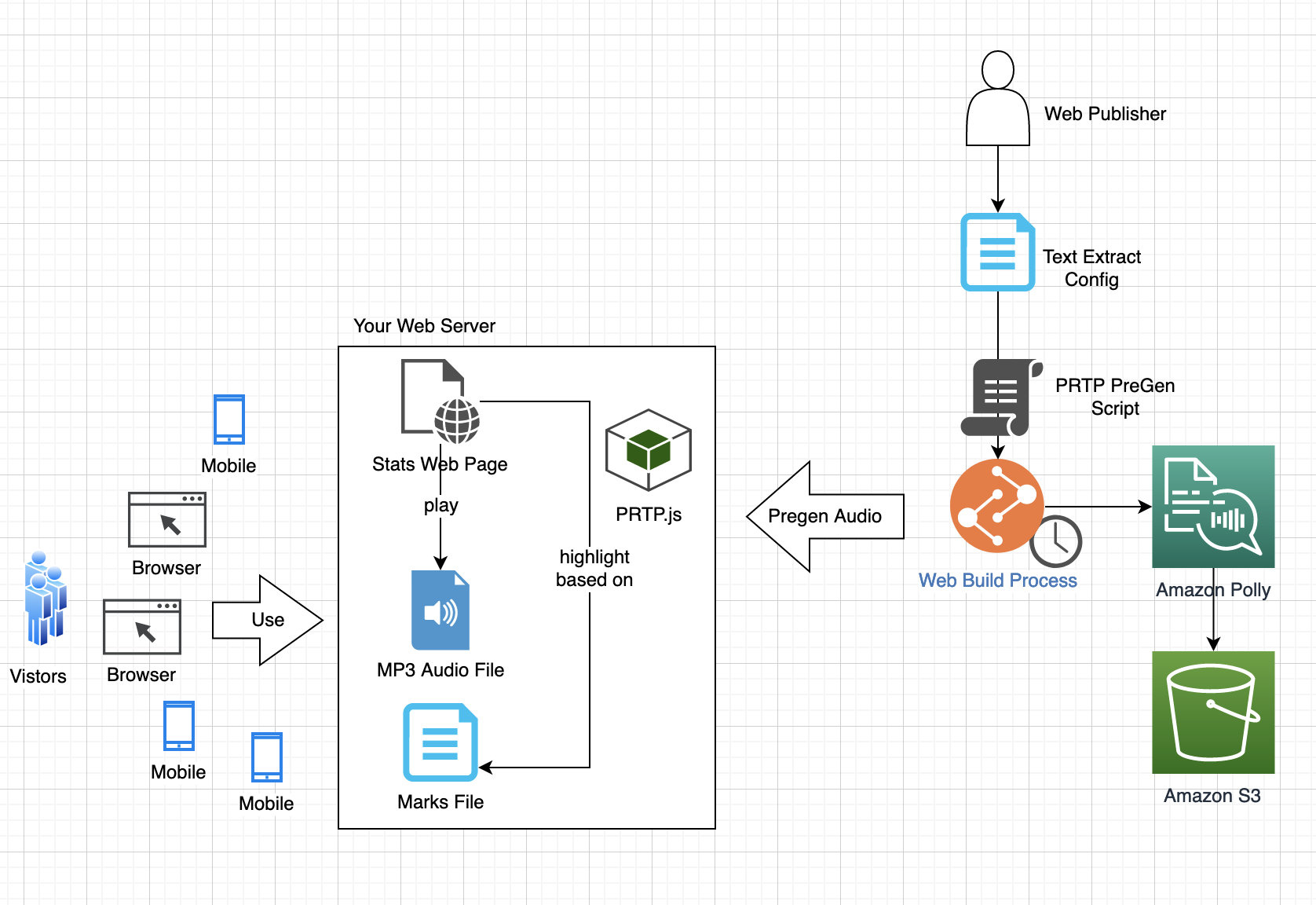
AWS はテキスト読み上げプロジェクトをどのようにサポートできますか?
Amazon Polly は、あらゆるテキストをリアルな音声に変換する完全マネージド型サービスです。使い方は簡単で、テキストファイルを Amazon Polly API に送信するだけで、すぐにオーディオストリームが返され、直接再生したり、MP3 などの標準オーディオファイル形式で保存したりできます。Amazon Polly では従量制料金が採用されており、リクエストごとのコストが低く、音声出力の再利用や保存に関する制限もありません。そのため、どこでも音声合成を実現できるコスト効率に優れたサービスとなっています。
例えば、Amazon Polly では次のことを行えます。
- テキストを何十種類ものリアルな音声と言語に変換して、あらゆるタイプのユーザーをサポートする。
- 必要に応じて、出力の速度、ピッチ、または音量を調整する。
- 追加料金なしで、生成された音声をキャッシュして再生する。
- リアルタイムのテキスト読み上げ機能を高速かつ大規模に実装する。
また、Amazon Polly チームと協力して、組織専用の合成音声を作成し、独自の音声アイデンティティでブランドを差別化することもできます。Amazon Polly は、HIPAA (1996 年の医療保険の相互運用性と説明責任に関する法律) および支払カード産業データセキュリティ規格 (PCI DSS、Payment Card Industry Data Security Standard) の規制対象ワークロードでの使用が認定されています。
今すぐ無料アカウントを作成して、AWS でテキスト読み上げの使用を開始しましょう。