生成 AI とは何ですか?
生成人工知能 (生成 AI または gen AI) は、会話、ストーリー、画像、動画、音楽などの新しいコンテンツやアイデアを生み出すことのできる AI の一種です。人間の言語、プログラミング言語、芸術、化学、生物学など、あらゆる複雑な主題を学習できます。生成 AI は、新たな問題を解決するために、知っていることを再利用します。
例えば、英語の語彙を学習し、処理した単語から詩を作成できます。
組織は、チャットボット、メディア制作、製品開発、設計など、さまざまな目的で生成 AI を使用できます。

生成 AI の例
生成 AI にはさまざまな業界でのユースケースがあります
金融サービス
金融サービス企業は、生成 AI ツールを使用して、コストを削減しながら、より優れたサービスを顧客に提供しています。
- 金融機関はチャットボットを使用して商品のレコメンデーションを生成し、顧客からの問い合わせに対応して、カスタマーサービス全体を改善しています。
- 融資機関は、特に発展途上国において、金融サービスが行き届いていない市場で融資の承認のスピードを上げています。
- 銀行は、請求、クレジットカード、ローンにおける不正行為を迅速に検出します。
- 投資会社は生成 AI の力を利用して、安全でパーソナライズされた財務アドバイスを低コストでクライアントに提供しています。
ヘルスケアとライフサイエンス
生成 AI の最も有望なユースケースの 1 つは、創薬と研究を加速することです。生成 AI は、特定の特性を持つ新しいタンパク質配列を作成し、抗体、酵素、ワクチン、遺伝子治療を設計できます。
ヘルスケアおよびライフサイエンス企業は、生成 AI ツールを使用して、合成生物学や代謝工学に応用するための合成遺伝子配列を設計しています。例えば、バイオ製造を目的として、新しい生合成経路を作成したり、遺伝子発現を最適化したりすることができます。
生成 AI ツールは、患者とヘルスケアの合成データも作成します。このデータは、AI モデルのトレーニングや臨床試験のシミュレーションのほか、現実世界の大規模なデータセットにアクセスせずに希少疾患を研究する場合にも役立ちます。

自動車と製造
自動車会社は、エンジニアリングから車載エクスペリエンス、カスタマーサービスまで、さまざまな目的に生成 AI テクノロジーを使用しています。例えば、機械部品の設計を最適化して車両設計における抵抗を軽減したり、パーソナルアシスタントの設計を適応させたりしています。
自動車会社は生成 AI ツールを活用して、顧客からの極めて一般的な質問に迅速に回答することで、より優れたカスタマーサービスを提供しています。生成 AI は、製造プロセスを最適化したり、コストを削減したりするために、新しい材料、チップ、部品設計を作成します。
もう 1 つの生成 AI のユースケースは、アプリケーションをテストするためのデータの合成です。これは、テストデータセットに含まれることが少ないデータ (欠陥やエッジケースなど) に特に役立ちます。

電気通信
通信業界における生成 AI のユースケースは、カスタマーエクスペリエンスの革新に重点を置いています。カスタマーエクスペリエンスは、カスタマージャーニーのあらゆるタッチポイントにおけるサブスクライバーのすべてのやり取りによって形づくられます。
例えば、通信業界の組織は、生成 AI を応用して、人間のようなライブ会話エージェントを使用してカスタマーサービスを改善しています。パーソナライズされた 1 対 1 のセールスアシスタントにより、顧客関係を革新しています。また、ネットワークデータを分析して修正を推奨することで、ネットワークパフォーマンスを最適化しています。
メディアとエンターテインメント
アニメーションや脚本から、完全な映画まで、生成 AI モデルは新しいコンテンツを、従来の制作にかかるコストと時間の数分の一で制作します。
業界における他の生成 AI のユースケースには次が含まれます。
- アーティストは、AI で生成された音楽でアルバムを補完および強化し、まったく新しいエクスペリエンスを生み出すことができます。
- メディア組織は、生成 AI を使用してパーソナライズされたコンテンツや広告を提供することでオーディエンスエクスペリエンスを改善し、収益を増やしています。
- ゲーム企業は、生成 AI を使用して新しいゲームを作成したり、プレーヤーがアバターを作成できるようにしたりしています。

生成 AI の利点
Goldman Sachs によると、生成 AI によって世界の国内総生産 (GDP) が 7% (約 7 兆 USD) 増加し、生産性の伸びが 10 年間で 1.5 %pt 上昇する可能性があります。次に、生成 AI のメリットをさらにいくつかご紹介します。
生成 AI 技術はどのように進化してきたのか?
プリミティブ生成モデルは、数値データ分析を支援するために統計学で何十年も用いられてきました。ニューラルネットワークと深層学習は、モダンな生成 AI の呼び水になりました。2013 年に開発された変分オートエンコーダー (VAE) は、リアルな画像と音声を生成できる最初の深層生成モデルでした。
VAE
VAE (変分オートエンコーダー) により、複数のデータ型の新しいバリエーションを作成できるようになりました。これにより、敵対的生成ネットワークや拡散モデルなど、他の生成 AI モデルが次々に登場しました。このようなイノベーションの重点は、人工的に作成されたにもかかわらず、実際のデータにより近いデータを生成することに置かれていました。

トランスフォーマー
2017 年、トランスフォーマーの導入により、AI 研究にさらなる新風が吹きました。トランスフォーマーにより、エンコーダーとデコーダーのアーキテクチャがアテンションメカニズムとシームレスに統合されました。トランスフォーマーは言語モデルのトレーニングプロセスを非常に効率的かつ汎用的に合理化しました。GPT のような注目すべきモデルは、幅広い未加工テキストのコーパスで事前トレーニングを行い、さまざまなタスクに合わせて微調整できる基盤モデルとして登場しました。
トランスフォーマーは、自然言語処理の可能性を変えました。これにより、翻訳や要約から質問への回答まで、さまざまなタスクに対応する生成機能が強化されました。

今後の展望
多くの生成 AI モデルは大きな進歩を続けており、業界を超えた応用の仕方が見出されました。最近のイノベーションは、独自のデータを処理するようにモデルを改良することに重点を置いています。研究者はまた、ますます人間に近いテキスト、画像、動画、音声を作成したいと考えています。

生成 AI の仕組みは?
すべての人工知能と同様に、生成 AI は機械学習モデル、つまり膨大な量のデータで事前にトレーニングされた非常に大規模なモデルを使用して動作します。
基盤モデル
基盤モデル (FM) は、一般化されたデータやラベル付けされていないデータに基づいて広範囲にトレーニングされた ML モデルです。基盤モデルはさまざまな一般的なタスクを実行できます。
FM は、何十年にもわたって進化してきたテクノロジーにおける最新の進歩の結果です。一般に、FM は学習したパターンと関係を使用してシーケンス内の次の項目を予測します。
たとえば、画像生成では、モデルは画像を分析し、より鮮明で明確に定義された画像を作成します。同様に、テキストの場合、モデルは前の数単語とそれらのコンテキストに基づいて、テキスト文字列内の次の単語を予測します。そのあと、確率分布手法を使用して次の単語を選択します。
大規模言語モデル
大規模言語モデル (LLM) は FM の 1 つのクラスです。例えば、OpenAI の生成事前トレーニング済みトランスフォーマー (GPT) モデルは LLM です。LLM は、要約、テキスト生成、分類、自由形式の会話、情報抽出などの言語ベースのタスクに特に重点を置いています。
LLM が特別なのは、複数のタスクを実行できる点です。これを実現できるのは、高度な概念を学習できるようにする多くのパラメータが含まれているからです。
LLM は、GPT-3 のようなに、何十億ものパラメータを考慮でき、ごくわずかな入力からコンテンツを生成できます。事前トレーニングでさまざまな形式や無数のパターンのインターネットスケールのデータに触れることで、LLM は幅広いコンテクストで知識を応用することを学習します。
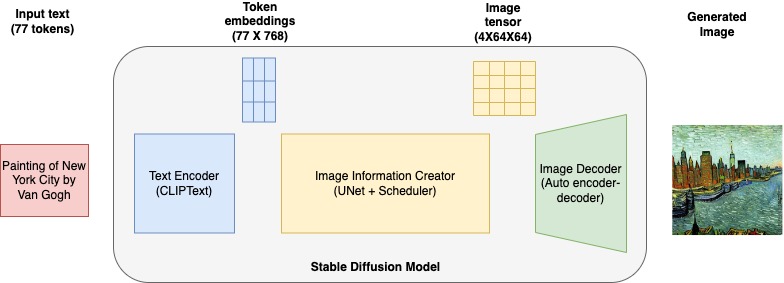
生成 AI モデルの仕組み
従来の機械学習モデルは、識別的であったり、データポイントの分類に重点が置かれていたりし、既知の要因と未知の要因の関係を特定しようとしました。例えば、ピクセルの配置、線、色、形状などの既知のデータである画像を見て、未知の要素である単語にマッピングします。数学的には、これらのモデルは、未知の要因と既知の要因を x 変数と y 変数として数値的にマッピングできる方程式を特定することで機能しました。生成モデルはこれをさらに一歩進めます。特定の特徴が与えられたときにラベルを予測するのではなく、特定のラベルが与えられたときに特徴を予測しようとします。数学的には、生成モデリングは x と y が同時に発生する確率を計算します。さまざまなデータの特徴の分布とそれらの関係を学習します。例えば、生成モデルは動物の画像を分析して、さまざまな耳の形、目の形、尾の特徴、皮膚のパターンなどの変数を記録します。それぞれの動物の特徴や関係を学び、さまざまな動物が一般的にどのような姿形をしているのかを理解します。その後、トレーニングセットに含まれていなかった新しい動物の画像を再現できます。次に、生成 AI モデルの大まかなカテゴリーをいくつか示します。
拡散モデル
拡散モデルは、初期データサンプルに制御されたランダムな変更を繰り返し加えることにより、新しいデータを作成します。元のデータから始めて微妙な変化 (ノイズ) を加え、徐々に元のデータとの類似度が低下していきます。このノイズは、生成されたデータが一貫性があり現実的な状態に保たれるように注意深く制御されています。
数回反復してノイズを追加した後、拡散モデルはプロセスを逆転させます。逆のノイズ除去によりノイズが徐々に除去され、元のデータに似た新しいデータサンプルが生成されます。
敵対的生成ネットワーク
敵対的生成ネットワーク (GAN) は、拡散モデルの概念に基づいて構築された別の生成 AI モデルです。
GAN は、2 つのニューラルネットワークを競争的にトレーニングすることで機能します。ジェネレーターと呼ばれる最初のネットワークは、ランダムノイズを追加して偽のデータサンプルを生成します。ディスクリミネーターと呼ばれる 2 つ目のネットワークは、実際のデータとジェネレーターが生成する偽のデータを区別しようとします。
トレーニング中、ジェネレーターは現実的なデータを作成する能力を継続的に向上させ、一方ディスクリミネーターは本物と偽物の見分け方が上達します。この敵対的なプロセスは、ディスクリミネーターが実際のデータと区別できないほど説得力のあるデータを生成するまで続きます。
GAN は、リアルな画像の生成、スタイル転送、およびデータ拡張タスクに広く使用されています。

変分オートエンコーダー
変分オートエンコーダー (VAE) は、潜在空間と呼ばれるデータのコンパクトな表現を学習します。潜在空間は、データを数学的に表現したものです。これは、すべての属性に基づいてデータを表す一意のコードと考えることができます。例えば、顔を学習する場合、潜在空間には目の形、鼻の形、頬骨、耳を表す数字が含まれます。
VAE は、エンコーダーとデコーダーの 2 つのニューラルネットワークを使用します。エンコーダーニューラルネットワークは、入力データを潜在空間の各次元の平均と分散にマッピングします。ガウス (正規) 分布からランダムサンプルを生成します。このサンプルは潜在空間のポイントであり、入力データを圧縮して簡略化したものです。
デコーダーニューラルネットワークは、このサンプリングされたポイントを潜在空間から取得し、元の入力に似たデータに再構築します。数学関数を使用して、再構築されたデータが元のデータとどの程度一致しているかを測定します。
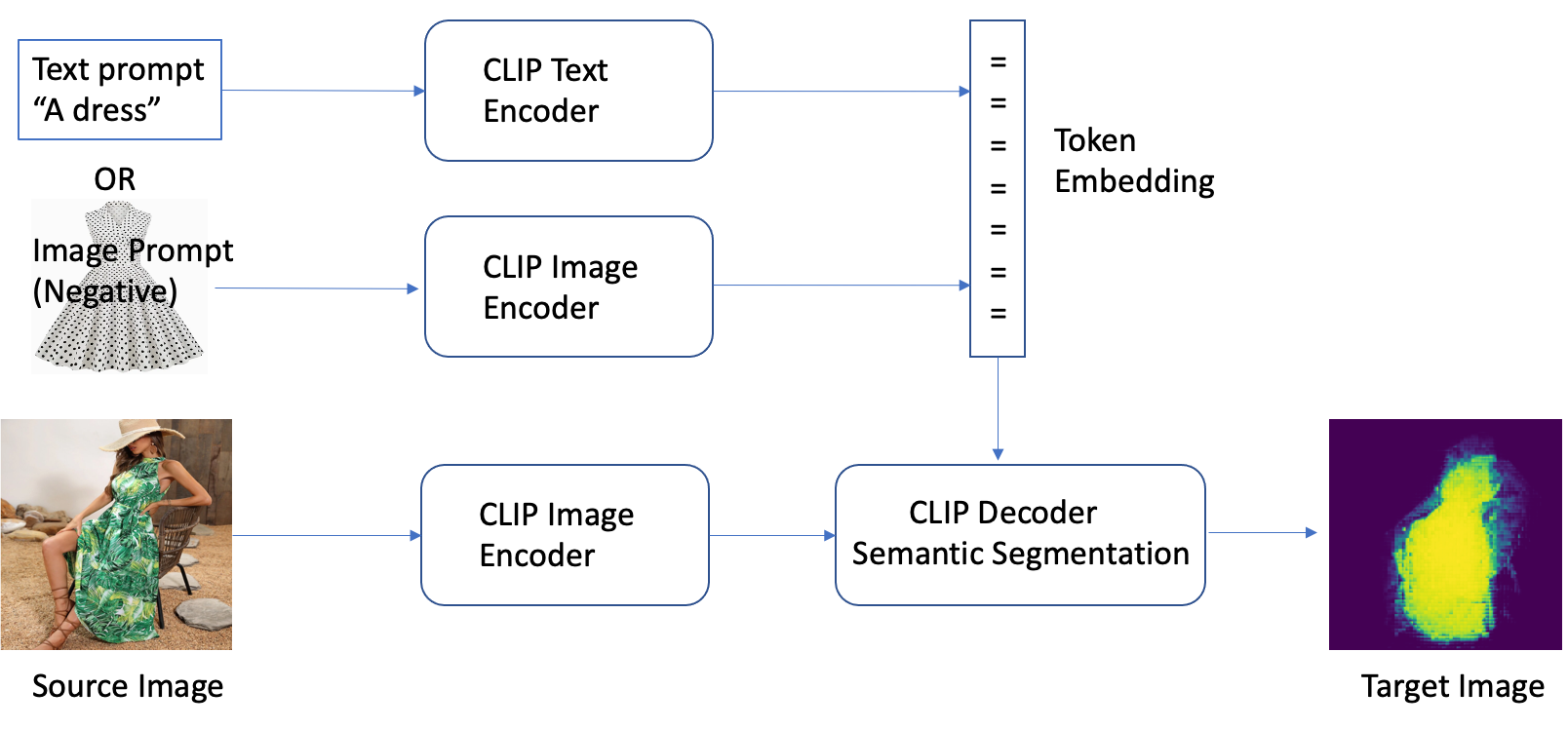
トランスフォーマーベースのモデル
トランスフォーマーベースの生成 AI モデルは、VAE のエンコーダーとデコーダーの概念に基づいています。トランスフォーマーベースのモデルは、エンコーダーにレイヤーを追加して、理解、翻訳、クリエイティブライティングなどのテキストベースのタスクのパフォーマンスを向上させます。
トランスフォーマーベースのモデルはセルフアテンションメカニズムを使用しています。シーケンス内の各要素を処理する際に、入力シーケンスのさまざまな部分の重要性を比較検討します。
もう 1 つの重要な特徴は、これらの AI モデルがコンテキスト埋め込みを実装していることです。シーケンス要素のエンコーディングは、要素自体だけでなく、シーケンス内のコンテキストにも依存します。
トランスフォーマーベースのモデルの仕組み
トランスフォーマーベースのモデルがどのように機能するかを理解するには、文を一連の単語として想像してみてください。
セルフアテンションは、モデルが各単語を処理する際に関連する単語に集中するのに役立ちます。トランスフォーマーベースの生成モデルでは、「アテンションヘッド」と呼ばれる複数のエンコーダーレイヤーを採用して、単語間のさまざまなタイプの関係を捉えています。各ヘッドは入力シーケンスのさまざまな部分を扱うことを学習し、モデルがデータのさまざまな側面を同時に考慮できるようにします。
また、各レイヤーではコンテキストに応じた埋め込みも洗練され、より有益な情報が得られ、文法構文から複雑な意味に至るまで、あらゆる情報が取り込まれます。
初心者のための生成 AI トレーニング
生成 AI トレーニングは、基本的な機械学習の概念を理解することから始まります。学習者は、ニューラルネットワークと AI アーキテクチャについても学ぶ必要があります。TensorFlow や PyTorch などの Python ライブラリの実践的な経験は、さまざまなモデルを実装および実験するために不可欠です。また、モデルの評価、ファインチューニング、プロンプトエンジニアリングのスキルも学ぶ必要があります。
人工知能または機械学習の学位の取得過程では、詳細なトレーニングを受けることができます。専門能力の開発のために、オンラインの短期コースの受講や認定の取得を検討してください。AWS での生成 AI トレーニングには、次のようなトピックに関する AWS エキスパートによる認定が含まれます:

生成 AI にはどのような制限がありますか?
生成 AI システムは、その進歩にもかかわらず、不正確または誤解を招くような情報を生成することがあります。同システムはトレーニングされたパターンやデータに依存しており、そのデータに内在する偏りや不正確さを反映している場合があります。トレーニングデータに関するその他の懸念事項には以下があります
セキュリティ
独自のデータを使用して生成 AI モデルをカスタマイズすると、データのプライバシーとセキュリティ上の懸念が生じます。生成 AI ツールが、専有データへの不正アクセスを制限するような応答を生成するように努力する必要があります。AI モデルの意思決定方法に説明責任と透明性が欠けていると、セキュリティ上の懸念も生じます。
AWS を使用した生成 AI への安全なアプローチについて学ぶ
創造性
生成 AI はクリエイティブなコンテンツを作成できますが、本当の意味でのオリジナリティに欠けていることがよくあります。AI の創造性は、トレーニングされたデータによって制限されるため、アウトプットが反復的だったり、派生的だったりするかもしれません。より深い理解と感情的な共鳴を伴う人間の創造性を、AI が完全に再現することは依然として困難です。
コスト
生成 AI モデルのトレーニングと実行には、かなりのコンピューティングリソースが必要です。クラウドベースの生成 AI モデルは、新しいモデルをゼロから構築するよりも利用しやすく、手頃な価格です。
説明可能性
生成 AI モデルは複雑で不透明なため、ブラックボックスと見なされることがよくあります。このようなモデルがどのようにして特定のアウトプットに到達するかを理解することは困難です。信頼と採用を高めるには、解釈可能性と透明性の向上が不可欠です。
生成 AI を採用する際のベストプラクティスとは?
組織が生成 AI ソリューションを実装したい場合は、以下のベストプラクティスにより取り組みを強化することをご検討ください。
AWS は生成 AI をどのように支援できますか?
Amazon Web Services (AWS) では、データ、ユースケース、顧客向けの生成 AI アプリケーションを簡単に構築してスケーリングできます。AWS での生成 AI を使用すると、エンタープライズグレードのセキュリティとプライバシー、業界をリードする FM へのアクセス、生成 AI を活用したアプリケーション、データファーストのアプローチを実現できます。